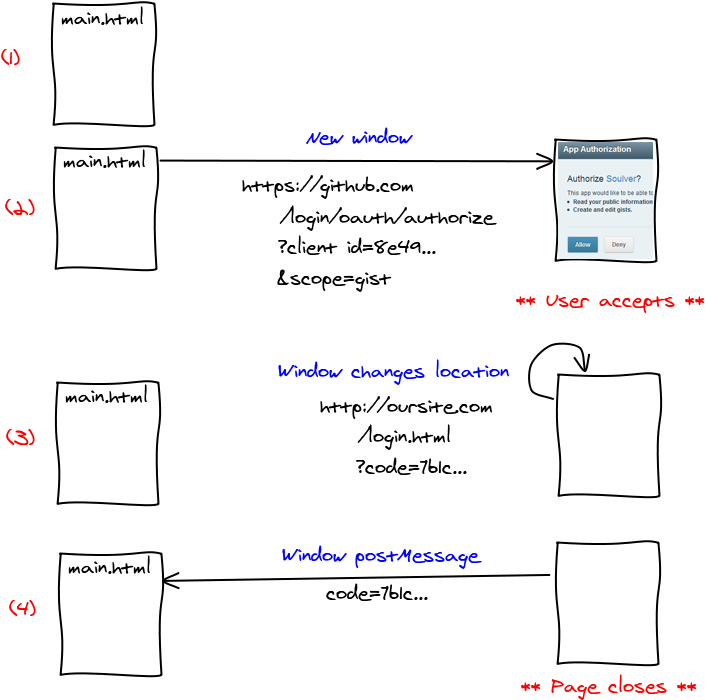
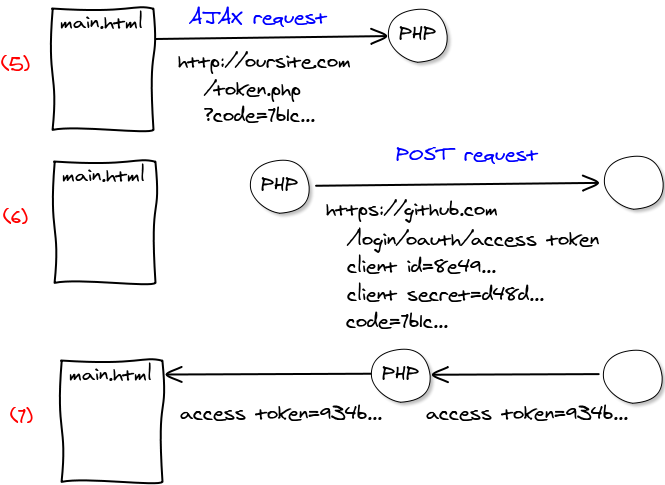
Using x-tags from Mozilla, we can write custom tags within the DOM. This is a great opportunity to be able to write reusable components without being tied to a particular library. I wrote x-react to have them being rendered in React.
Example
We're first going to write a regular React component.
var Hello = React.createClass({ render: function() { return <div>{'Hello ' + this.props.name}</div>; } }); |
Then, we use xreact.register to bind a React component to a custom tag name.
xreact.register('x-hello', Hello); |
At this point, any
<x-hello name="World"></x-hello> |
The rendered DOM tree lives in the shadow DOM. This lets us manipulate both the <div> using Web Inspector.

Anytime you modify the
Behind the scenes
When you call xreact.register, we call xtag.register saying that whenever an XReact in the shadow root of <x-hello>.
xtag.register('x-hello', { lifecycle: { created: function() { React.renderComponent( XReact({element: this}), this.createShadowRoot() ); } } }); |
XReact is a really simple component that takes a DOM node, in this case <x-hello name="World" /> and converts it to the React equivalent: Hello({name: 'World'}).
var XReact = React.createClass({ render: function() { return convertDOMToReact(this.props.element); } |
MutationObserver gives us a callback whenever the this.forceUpdate() to make sure the React rendered version stays in sync.
componentDidMount: function() { new MutationObserver(this.forceUpdate.bind(this)).observe( this.props.element, {/* all the possible mutations */} ); } ); |
That's it 🙂
Conclusion
It was really easy to make this small bridge in order to be able to create custom tags and have them rendered using React. Unfortunately, this experiment is only working on Chrome as it is relying on MutationObserver and Shadow DOM.