Jul
14
This talk was recorded for React Europe 2020.
It's April 1st on Monday and Clippy is a good candidate for fun pranks on websites. Sadly I couldn't find any readily available gifs for it. Closest I saw was this youtube video that shows all the animations back to back. So with a bit of video editing I extracted the 23 animations of them into transparent gifs. You can also download them all in clippy.zip. Happy pranking!














































I've been at this company for 12 years today and it feels like a good time to reflect on all the projects I've been involved in!
I found out over time that the projects where I thrive are spaces where the R&D phase is over and the tech now works but it needs to be turned into a proper product to start the exponential growth phase. My biggest strength is getting people excited about the crazy projects and working together. "Connecting People" is deeply ingrained into me!
My bootcamp task was an open ended “use the new face.com bounding boxes to improve tagging”. I made a lot of UX tweaks so that you could tag a whole album only pressing enter and down arrow which led to huge increase in terms of number of tags on Facebook.
The best part is that it was a lot more than just tagging. That notification was the highest click through rate of the entire site: everyone wants to know how they look. So increasing it led to increased engagement. So improving the AI model for face detection and/or recognition directly led to engagement. This was the first time we had this positive feedback loop outside of newsfeed for an AI model.
We also used face information to better crop images when we had to. Instead of cropping on the center, we find the crop where we can fit most faces. This drastically reduced the number of awkward crops.
I joined the Photos team to work on the photos page of your profile, was the third most visited page with billions of impressions a week. I wasn’t even out of college (was officially my final internship). Crazytown.
Anyway, I did a study of all the layout algorithms for displaying images across the industry and ended up implementing one. It wasn’t really a groundbreaking success (though newsfeed multi-image layout is still built on my findings today!) but as part of building it I struggled to find how to display images of the right size.
It turns out that I wasn’t the only one struggling and we were sending the wrong sizes all over the website. I ended up building an API to abstract away all the sizing computation and converted the biggest callsites.
The first conversion saved single digit percentage of total Facebook egress. Not only that but having a way to programmatically find sizes meant that we could stop storing awkwardly sized pictures on upload which let us delete double digit percentage of photos storage the next year. This is still being used to this day!
My main contribution with React was not technical but around building a community around it. In the very early days I would do a weekly summary of everything happening in React to generate buzz around it.
After a year, the community was big enough that I ended up organizing the massively successful initial React.js Conf and was heavily involved in the first few other conferences that popped up such as React Europe in Paris and React London.
I also encouraged people internally to talk about GraphQL during the first React.js Conf which ended up becoming another massive project on its own.
More recently, I got the original crew to participate in the React Documentary.
I participated in the initial hackathon that led to the React Native project and worked on it for a couple of years afterwards. The goal was to help with the Mobile First transition that Facebook was into at the time.
React Native nowadays is really successful. About 20% of the top 100 apps in all the US app store categories ship with the React Native SDK.
Internally, Marketplace (which is bigger than Craigslist btw), Ads Manager mobile and a long tail of features like Crisis Response.
Our AR/VR technology is heavily dependent on it. All the 2D in-headset surfaces are built with React Native. All the companion apps of our hardware (Quest, Rayban…) are built with React Native too.
As part of the project I reimplemented a way to layout elements following the flexbox CSS specification. It was called originally css-layout and later renamed to Yoga.
The rationale behind this project is that all the layout algorithms implemented by app frameworks (iOS, Android, Web…) were all different and incompatible but did the same thing. If we wanted to be able to share code between platforms, we needed to have a single one. And you could implement a different one on all the platforms except for web.
It was successful for React Native and was later used by ComponentKit (iOS) and Litho (Android). This not only had a massive impact on its own but also meant that when the Bloks project came to be (driving UI from Hack with XHP), you could actually write things once and it would work on all the platforms. Including web when Bloks.js effort was started.
This keeps on giving wins, Threads was built using it and they could get three implementations working in such a short amount of time.
In order to avoid having a similar backslash when we announced React where we mixed HTML and JS together, I went to a conference and talked about how mixing CSS and JS together could have a lot of advantages.
As expected this was very controversial but also spawned an entire ecosystem of libraries to make it work and change the way people write their front end code.
I spent 3 months trying to implement React Native styling system on our web stack but there wasn’t a lot of appetite for it. Until we decided to rewrite the entire front end stack with Comet and this was picked up under the name Stylex. We just open sourced it a few months ago and it is how all CSS at Meta is being written nowadays.
While people were really excited about React Native for the cross platform aspect, our first focus was on making it a way better experience on a single platform compared to the status quo.
The rest of the ecosystem took notice. The tech lead who drove Airbnb’s adoption of React Native moved to Google to build Jetpack Compose using very similar ideas. Apple secretly worked on a competing framework for years called SwiftUI using the same paradigm. Google built Flutter.
It’s not a secret that I’ve been a huge advocate for Open Source within the company, living to the "Make the world more open and connected" early mission of Facebook. A few years ago I looked and I was personally involved in half of the top 20 most popular Meta projects.
For every open source project we have, we need to build a website for it. When React was released I used React to build its website (even if we didn't use it). Then, I copy pasted (yeah…) it for our next multiple projects: Jest, GraphQL, Watchman…
At some point the open source team got an intern who took my copy pasted website and packaged it into a proper tool called Docusaurus.
This is now what we use to create websites for most of our open source projects. The project is also open source and I regularly see it being used for many open source projects in the industry too.
There’s a huge question for open source projects as to where the source of truth lives. Either on github or in our own codebase.
For github first projects, the story is relatively simple where everything happens on github and once in a while we import the whole thing internally and use it as any other third party dependencies.
But if you want to be internal first, then you need to be able to import pull requests as internal diffs after a manual spot check from an employee, send sanitized CI feedback to the pull request and synchronize all the commits landed internally to github.
Well, I built a lot of that infrastructure for React Native and it’s been used ever since by all the open source projects that are internal first, which includes PyTorch.
We started the React community on IRC but it showed its age and the Reactiflux slack channel started gathering a lot of usage. Until Slack decided that it wanted to focus on company use case and started charging by user. They gave a $100k+ monthly bill so it had to move somewhere else.
I started looking at options and honestly they were all terrible. Except for an unlikely one: Discord. It was a gaming-focused app mostly for voice at the time. I helped their CTO with React Native questions a few years earlier as they were one of the first to use it for their mobile app.
I ended up orchestrating the move that has been a great success in itself. But what happened is that it started a trend within the open source community where discord eventually became the place where all the projects built their community there.
Discord created a specific variant of their product for open source community and then eventually rebranded their entire company to not only focus on gamers but everyone.
I like doing side projects but I found it way too annoying to get started in the JavaScript stack compared to my trusted old PHP, so I wrote a challenge to improve the status quo.
Turns out two people took on the challenge and ended up creating two successful companies out of it: CodeSandbox and StackBlitz! Pretty incredible how framing a problem can have such a large impact.
When I started working on Prettier in 2017, nobody at Meta believed in automatic full code formatting on proper programming languages.
I’m so happy that the state of the world is the opposite now, where programming languages that are not automatically formatted are the exception.
Some of the timeline and highlights.
It’s been a very long road filled with many many people that spent their time removing all the roadblocks both technical (CI, linting, codemods, land, IDE integration…) and non-technical (convincing people that it’s a good idea).
I’m so proud that Facebook has been leading the way in the industry there where both prettier and black originated here.
I was using the annual JavaScript survey where they ask people what tool they used in the industry. Sadly a few years ago they just stopped asking the question because “prettier is like git, everyone’s using it”.
Prettier is also relatively (in open source standards) well resourced with $120k total donations. I’ve been paying two people $1.5k a month to keep it maintained for the past two years.
I’m also glad that I never have to format my code anymore. It’s such a waste of time, both when editing code and puts people in a situation of conflict when doing code review for no good reason.
I joined Client Foundation, which is building all the tooling for managing client-side performance and reliability of Facebook, Instagram, Messenger for iOS, Android and Web. The pitch was that the org had too many tools and customers found them confusing, ugly and data was not to be trusted and they needed help to solve the problem.
I first looked at the composition of the org and there was 0 PMs, 0 designers and a handful of UIEs, but mostly not working on UI. This was clear that we needed to change things on that front to be successful. I started hiring folks and transitioned to be a manager to support them.
A lot of education was needed around what is the role of UX in a pure infra org. The most effective way I found to do this is by being super involved in running Client Foundation calibrations and organizing company wide UIE Mashups.
When I moved out I was managing 25 people in an org of 150 people. And we had 3 PMs and 3 Designers. So about a 1/5 ratio of UX folks which made sense.
The product strategy I pushed for is to have a single definition for what a metric is. Having this lets us build tooling that works together instead of being a lot of one offs.
The first step was to “fake it until you make it”. The advantage of working on the front-end is that it’s a lot easier to change things. This is where Perf Overview / CV Home was born.
We would display the topline metric, experiments regressing the metric, main QPL points and a few others. The way we decided what to build was data driven. We would look at real SEVs that happened and count how many times a particular data source would be useful.
JoBerg did a big vision exercise and the main realization was that our customers were not product teams but Product Foundation. This made us invest in a new offering: Program Runner.
The Facebook app historically was only focused on startup performance and newsfeed scroll performance. This made sense since this is where a large part of time spent. But in practice Facebook has many sub products inside which if they are bad, taint the entire experience of users.
So Product Foundation strategy changed to have baseline metrics for dozens of teams across iOS and Android. And we enabled this with Client Foundation tooling working together for the first time.
Release Engineering would join Client Foundation and I was asked to help with their product strategy.
The #1 job of Releng was to shepherd the releases of www and our mobile apps. But the TPMs working on mobile releases would literally last 3 months and quit because the process was so stressful and all time consuming.
This is when operation “Make Chris Happy” (another Chris) started. We did a deep dive into all the tasks he had to do in order to do a release and implemented them into a new tool called Flight Deck.
This massively improved the release process for mobile releases and has since been expanded to all the surfaces Releng supports.
I’ve been using a tool to draw handwritten-like images for my blog post for 15 years at this point. But in January 2020 the tool broke and I decided to reimplement it for fun.
I had no idea that 3 months later Covid would hit and send everyone home and creating a market for a virtual whiteboard. It turns out that excalidraw, even though it was only 3 months old, was the best tool at that time.
All the tech companies, Facebook included, started to use it for their interview process. In addition it became used for a lot of the day to day activities such as brainstorming, architecture diagrams, notes illustrations…
In order to increase its reach, I convinced two people to create a company to support a SaaS product around it. Turns out even though it’s end to end encrypted and open source, lots of companies don’t feel comfortable to use it for their internal documents if a company isn’t behind it.
The company is striving with 10 full time employees, revenue positive without any investment. It supports the open source version which gets meaningful updates every year, which we use at Meta.
A few companies were built on the success of excalidraw and raised multiple million dollars. Tldraw which is a spinoff from a contributor of Excalidraw. Eraser which builds a meeting side-view using excalidraw.
Having a good virtual whiteboard is likely to be a core part of any working environment down the line. Covid got people to be looking for it but it keeps being useful even after people came back to the office.
While I’ve been focusing my work on the front-end space, I actually studied Computer Vision and AI at my school. I’ve been closely following the AI space which have been booming ever since I joined Facebook with “deep learning”.
When ChatGPT started making waves, I was quickly convinced that we needed to have something like it for employees trained on our codebase, wiki, feedback groups…
Thankfully, the company prioritized it and a big team was quickly formed around the project. I made a few key decisions to ensure that the project that became Metamate would be successful as a lot of people jumped in:
This project felt like the early days of Facebook where a bunch of people banded together to work and ship cool stuff quickly!
Sheryl Sandberg has been a huge inspiration for me. I’ve made a personal commitment to do what I can to make the women around me successful.
I make time to attend women related events to learn what are the challenges they are facing such as the yearly Women in Leadership Day. I have proactively organized many meetups for women within Client Foundation and DevInfra women managers. I also prioritize mentoring high performing women.
As a result of all the above, I’ve been able to hire amazing women to the teams I’ve been on. In Client Foundation, there was around 50% women/men ratio all the way up to 25 people in my organization. We're currently at 8 / 20 in my current team.
This is hopefully going to change the industry for the better!
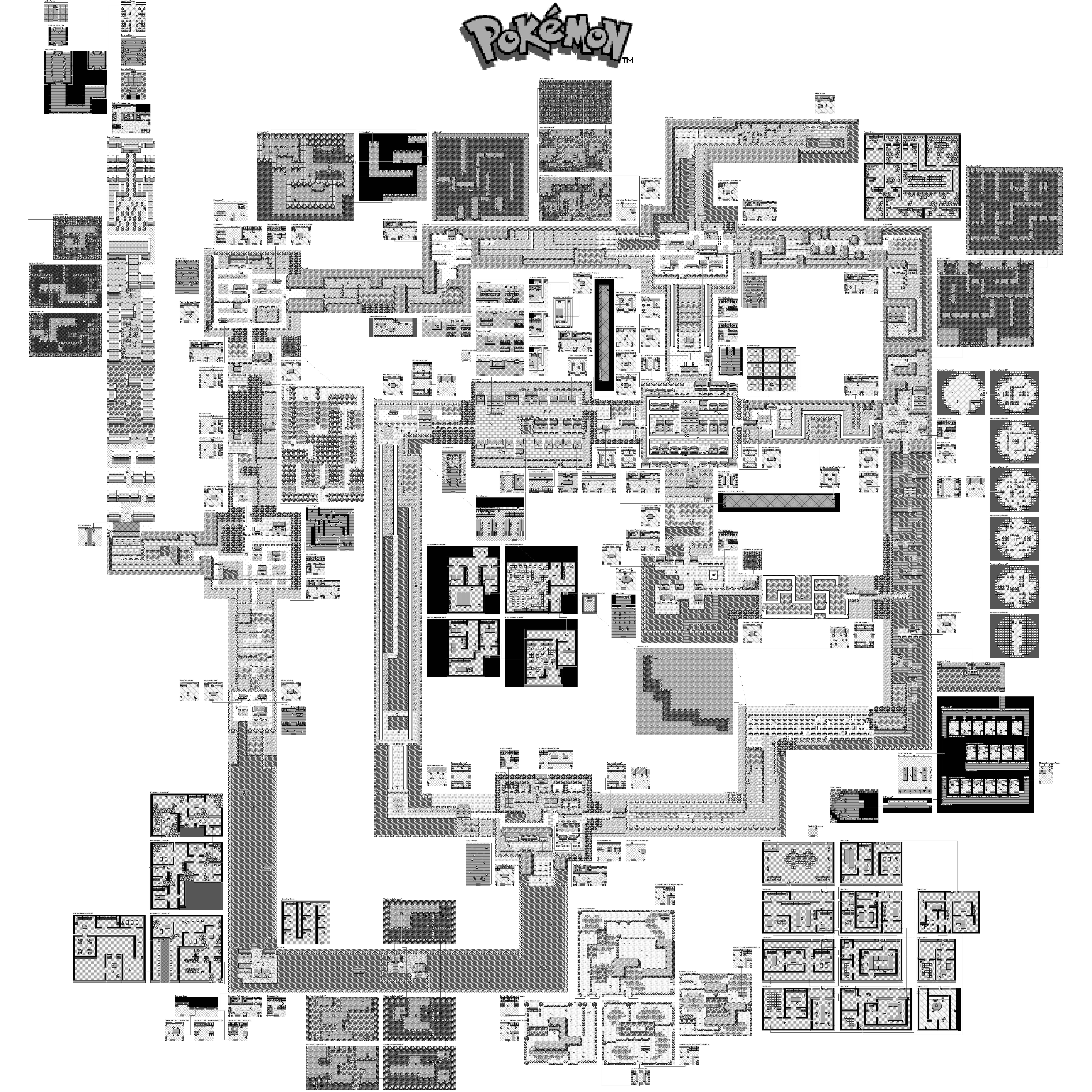
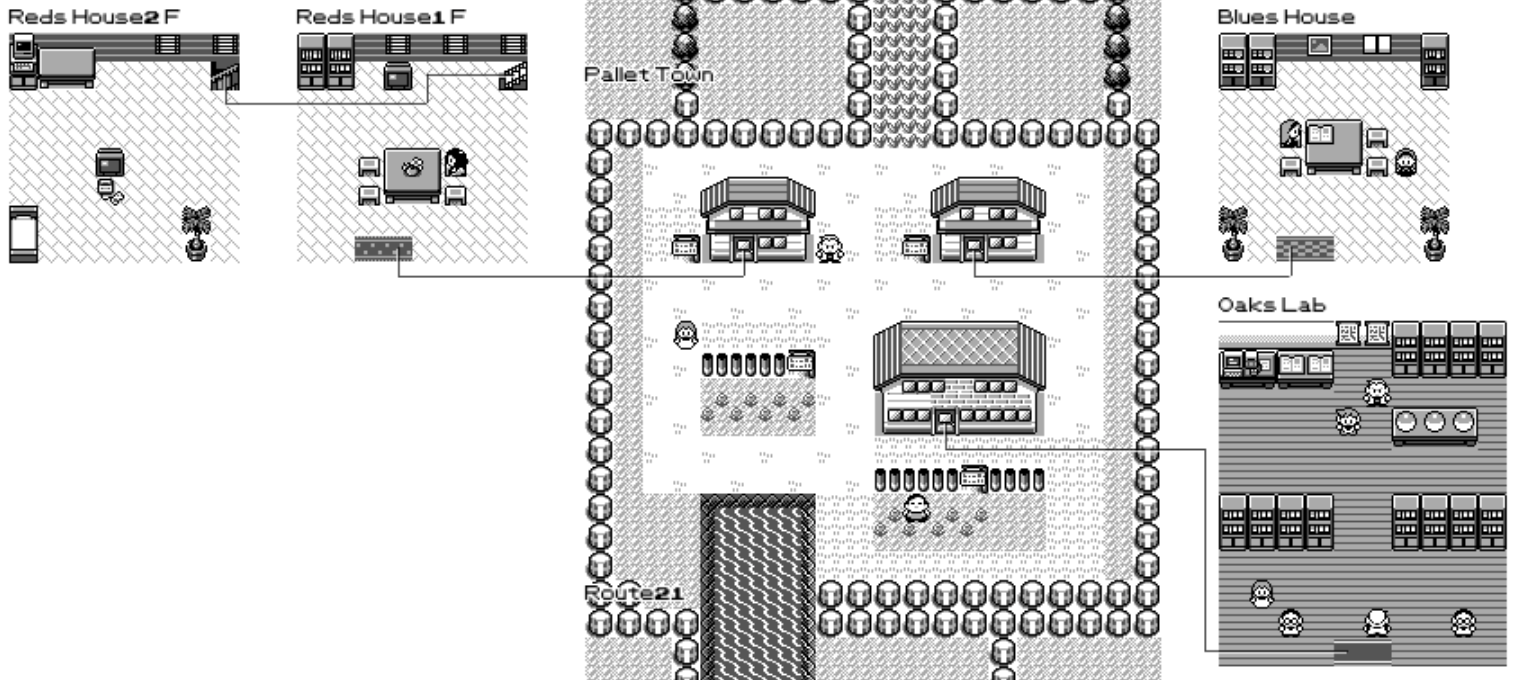
I randomly stumbled upon Peter Hajas rendering of Pallet Town and got super excited. I played Pokemon Red/Blue when it was released as a kid and played it again with my daughter when she was the same age. This game is really awesome and stood the test of time.
But, I've been very frustrated that I've never seen a proper map of the entire game. All the ones I've seen are just of the overworld but don't contain all the inside of buildings or caves, which is where you end up spending a lot of your time.
So, I spent the last month working on a full rendering of the map. And it's done just in time for Christmas 🙂 I used a lot of algorithms in the process and figured that you may be interested in it. This is the final 7200x7200 map, click to see the full version or run it yourself!
We need to start by rendering a single map of the game. For this, I used Peter Hajas's awesome explanations along with the awesome disassembly of the pokemon game: the pret/pokered project. I got Pallet Town rendered!
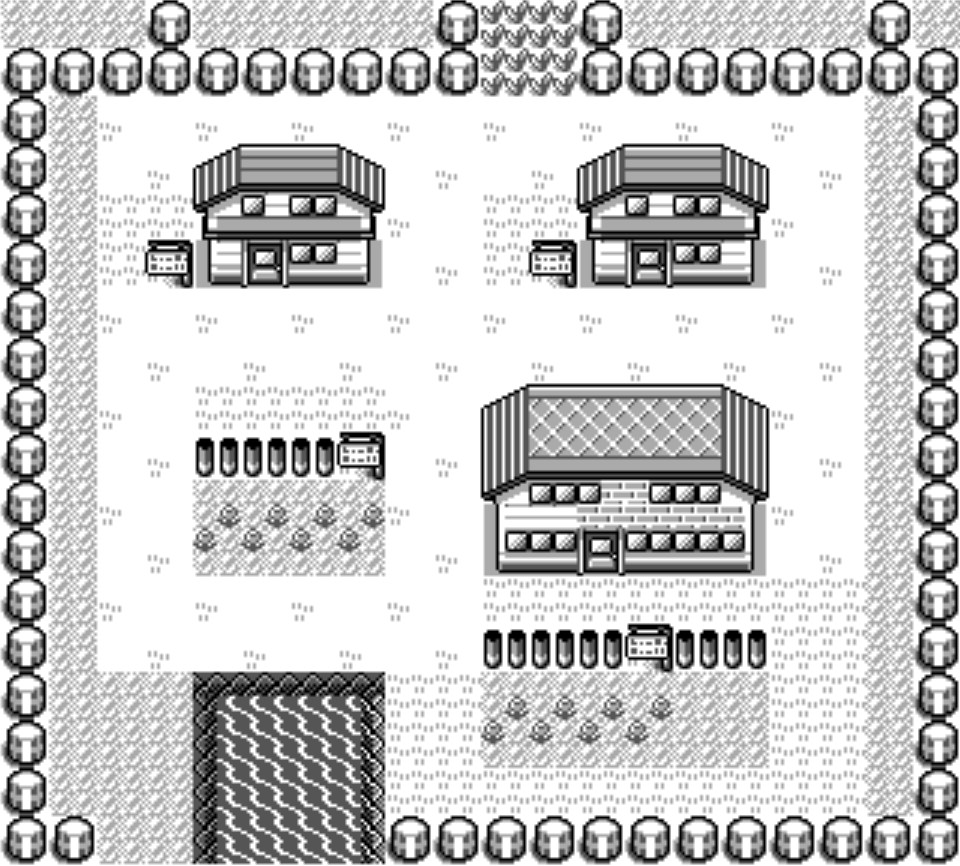
A single map is nice but you want to see the next map going to the edge. For this, the information is stored in headers files, one for each map. It contains the connections with other maps. In this case, north is Route 1 and south is Route 21.
// pokered/data/maps/headers/PalletTown.asm map_header PalletTown, PALLET_TOWN, OVERWORLD, NORTH | SOUTH connection north, Route1, ROUTE_1, 0 connection south, Route21, ROUTE_21, 0 end_map_header |
You can now recurse and display all of Kanto's overworld with it. The loop looks something like this where we keep a visited object with all the map names and whenever we visit a map, we add the connections to the todos list. Note that I keep a fail safe with Object.keys(visited).length < 100 to avoid going into infinite recursion if I make a mistake.
const todos = [{ mapName: "PalletTown", pos: {x: 0, y: 0} }]; const visited = {}; while (todos.length > 0 && Object.keys(visited).length < 100) { const mapTodo = todos.pop(); if (visited[mapTodo.mapName]) { continue; } visited[mapTodo.mapName] = true; drawMap(mapTodo); const metadata = getMapMetadata(mapTodo.mapName); metadata.connections.forEach((connection) => { if (visited[connection.mapName]) { return; } todo.push({mapName: connection.mapName, pos: computePosition(...)}); }); } |
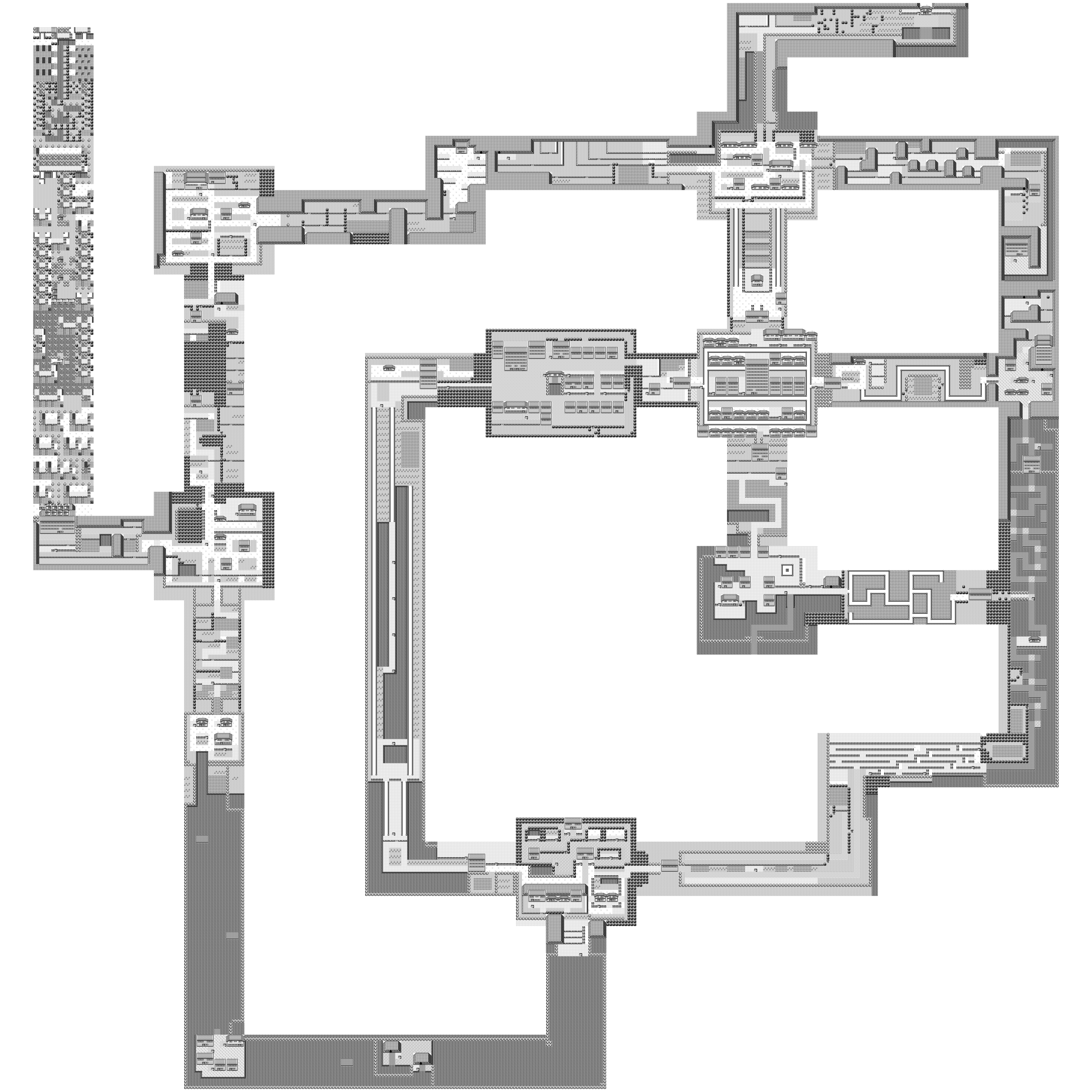
This is the map that I was familiar with from playing the game! But if you have a good eye, you'll notice that the route leading to the elite four is all nonsense. What gives?
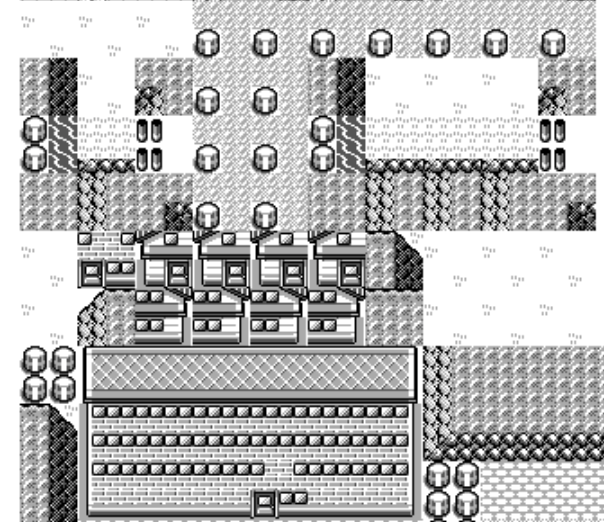
The problem is that we hardcoded a single tileset, the overworld one. But route 23 leading to Indigo Plateau has a different one "plateau".
We now run into an issue that's related to the browser, while we were able to use the deprecated synchronous XHR call to load all the map files, in order to draw the images to the canvas, there aren't any synchronous APIs available.
In order to fix this, we split the rendering into 4 parts: going through all the data to generate a list of draw calls. Then, we can parse that list to find all the images we need and load them, and finally once they are all loaded we can do the rendering pass.
// Phase 1: Push all the draw calls to an array drawCalls.push({ type: "tile", tilesetName: "overworld" | "plateau", ... }); // Phase 2: Extract all the images const tilesetNames = {}; drawCalls.forEach((drawCall) => { if (drawCall.type === "tile") { tilesetNames[drawCall.tilesetName] = true; } }); // Phase 3: Load the images const tilesetImages = {}; Promise.all([ ...Object.keys(tilesetNames).map((tilesetName) => { return new Promise((cb, raise) => { const image = document.createElement("img"); image.onload = () => { tilesetImages[tilesetName] = image; cb(); }; image.src = tilesets[tilesetName]; }); }), ]).then(() => { // Phase 4: Execute the canvas operations drawCalls.forEach((drawCall) => { if (drawCall.type === "tile") { context.drawImage( tilesetImages[drawCall.tilesetName], ... ); } }); }); |
And with this, we solved not only tilesets but all the images we'll need to include in the future. And, the route to Indigo Plateau doesn't look like a mess anymore.
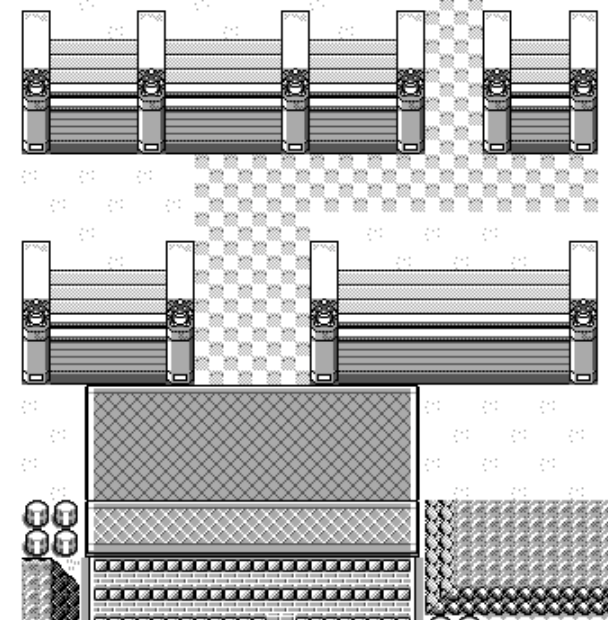
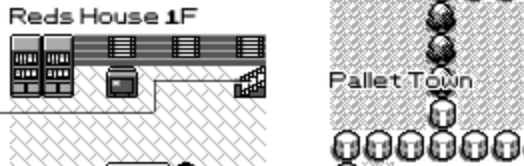
At this point we got what you can see in most full pokemon maps, but I really want to get all the houses, caves, safari zone... to show up!
The way to think about the problem is that when you enter the player's house via the door (in blue), you get warped to the mat in the room (in red).
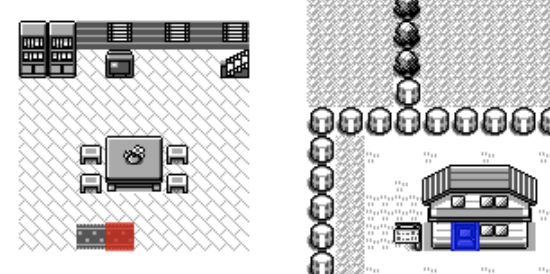
So the idea is that we're going to try and overlap the rendering of the inside of the house such that the door and the mat are on-top of each other. This will give us the coordinate at which we're going to draw the map (in green).
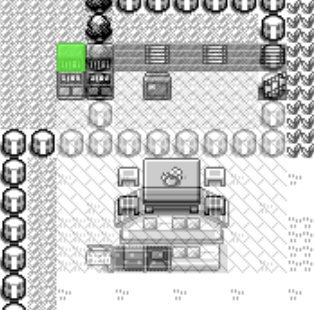
And we are going in a circle around that starting location until we find a position that is not going to collide with anything.
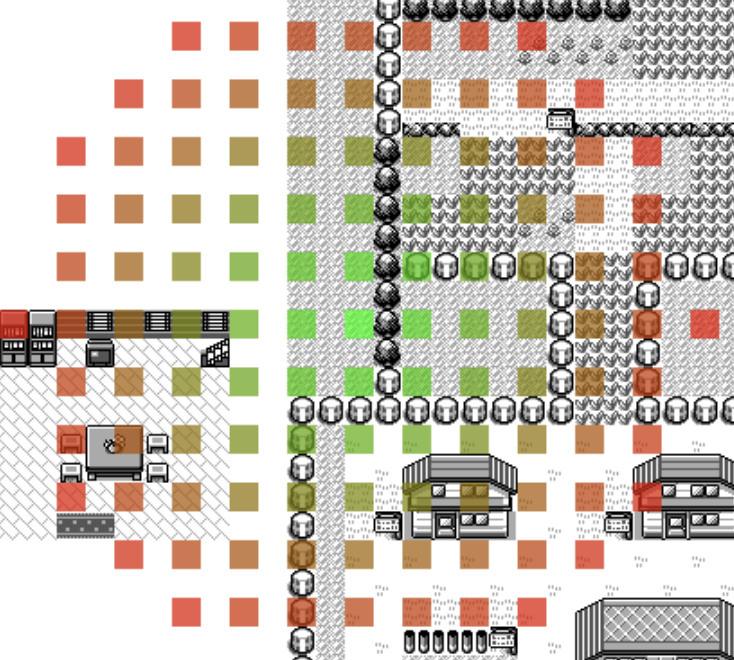
You may wonder why I only do an attempt every 4 positions... well, the truth is, I used the map coordinates but didn't realize that the game is actually fitting 4 tiles per block. But, it turns out to be very useful in practice to leave such gaps to draw arrows down the line.
There is probably an algorithm to visit cells in a grid going out in a circle but I couldn't find an easy way to write it myself. So instead I used a shortest path algorithm. I use a priority queue that picks the smallest distance from the center (note, you can use Math.hypot to do it!) and abuse objects in JavaScript by having coordinates as keys as string "12:4" and value of true to indicate that we already visited it.
const queue = new PriorityQueue((a, b) => Math.hypot(a.x - x, a.y - y) < Math.hypot(b.x - x, b.y - y) ); const visited = {}; let x = map.x + Math.floor(warp.x / 2); let y = map.y + Math.floor(warp.y / 2); queue.push({x, y}); visited[x + ":" + y] = true; const deltaX = Math.floor(nextWarp.x / 2); const deltaY = Math.floor(nextWarp.y / 2); while (!queue.isEmpty()) { const pos = queue.pop(); if (isEmpty(pos.x - deltaX, pos.y - deltaY)) { return { x: pos.x - deltaX, y: pos.y - deltaY, }; } for (let p of [ [{x: pos.x - 1, y: pos.y}], [{x: pos.x + 1, y: pos.y}], [{x: pos.x, y: pos.y - 1}], [{x: pos.x, y: pos.y + 1}], ]) { if (!visited[p.x + ":" + p.y]) { queue.push([p.x, p.y]); visited[p.x + ":" + p.y] = true; } } } |
The isEmpty function is just a double loop that checks if all the slots in the map are empty. You may realize that this is a O(n^3) algorithm but I have a trick to make it faster. I first do a check to see if the four corners are empty. Given the way all the maps are layout, in practice this heuristic is really close to perfect, so we are no longer quadratic.
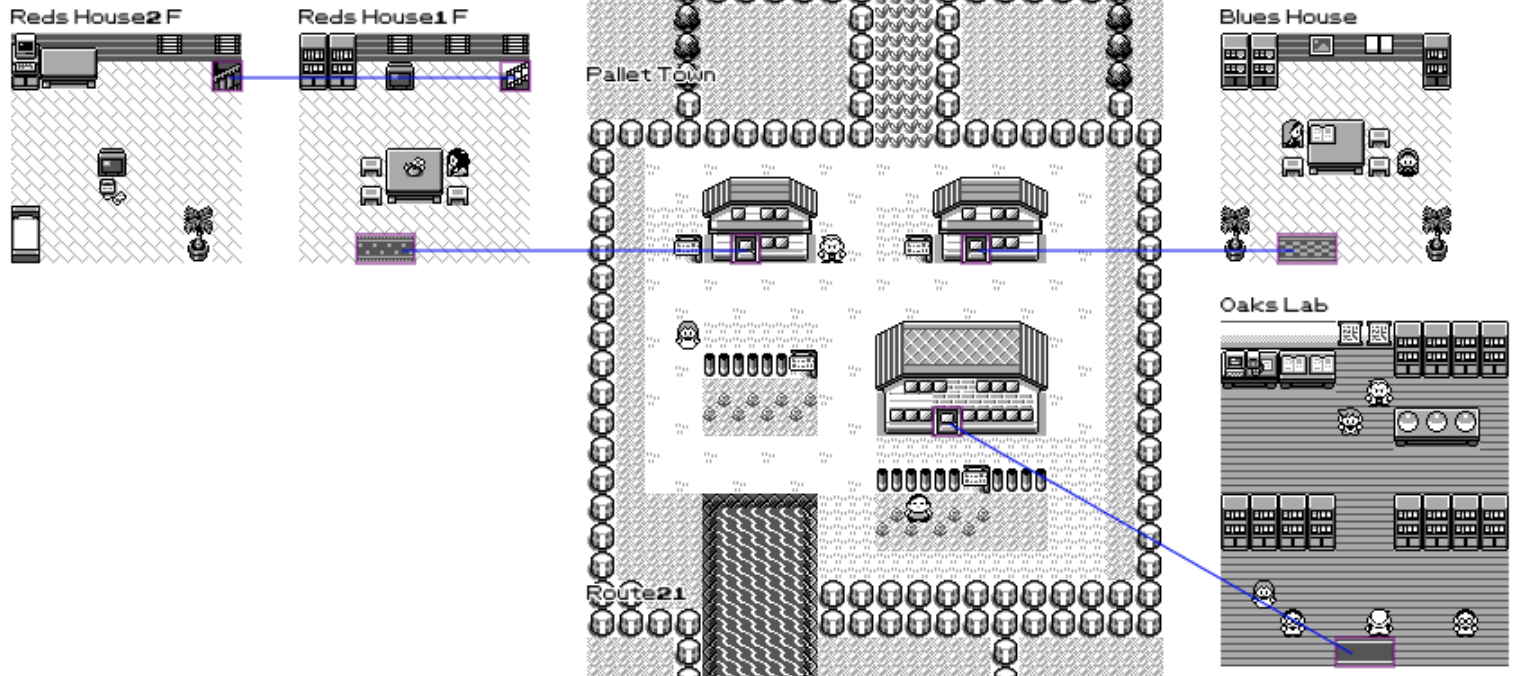
Now, we can repeat this algorithm for every single warp point and we can draw all the sub-maps of the game close-ish to where the warp points are! The following is how Pallet Town is rendered using this technique.
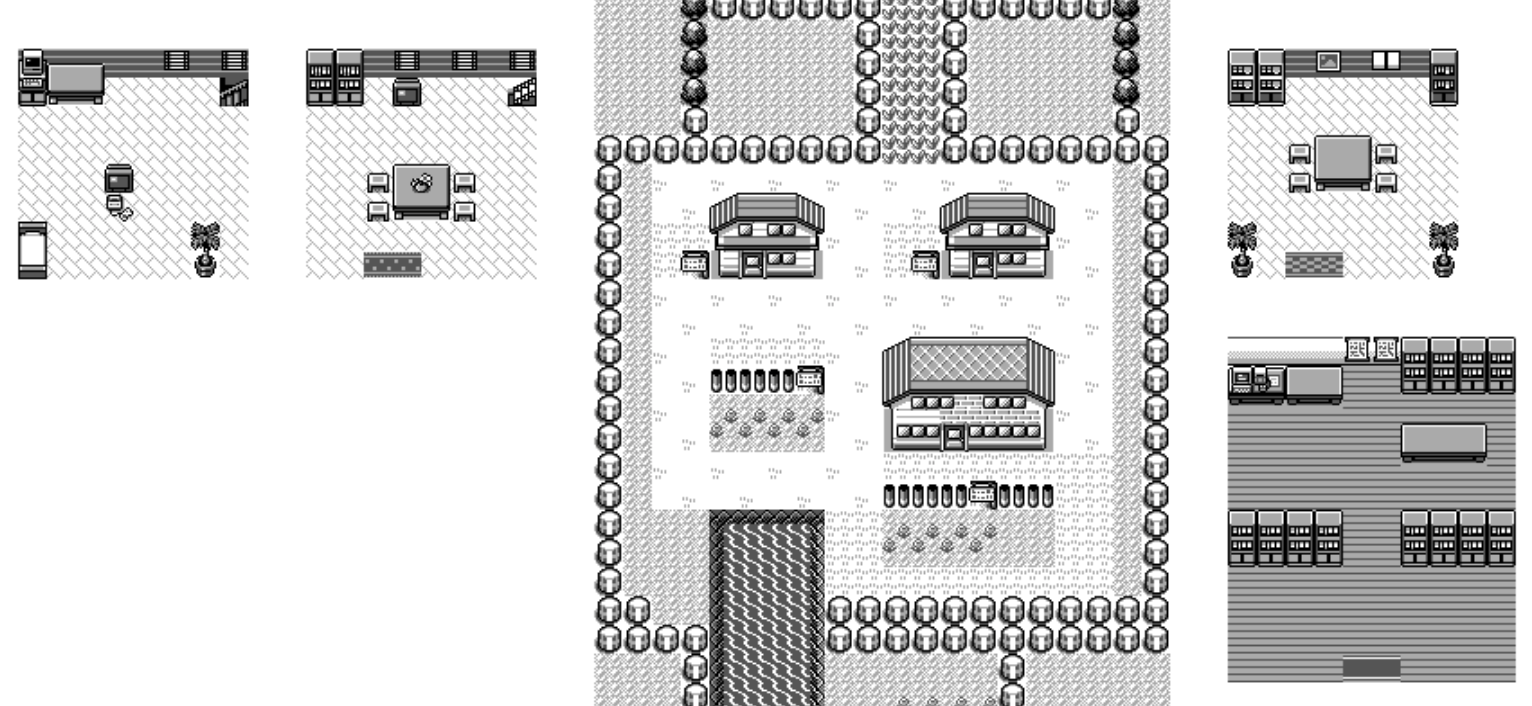
This is called a "greedy" algorithm, where the first map that we place is placed forever and then the next maps have to find a position that would work. But this is not generating optimal layout where knowing the next maps we need to place, we could move the first one in a better position.
Sadly, those algorithms are a lot more expensive to run and also it's unclear whether it would find solutions that would be significantly more aesthetically pleasing. As a result, I ended up manually repositioning around half the maps. Having a base algorithm to work with was still extremely useful as I would just have to do touch ups instead of having to do everything from scratch
The pokered repository has for each map the location of all the sprites and has already done the work of converting compressed pixels to png.
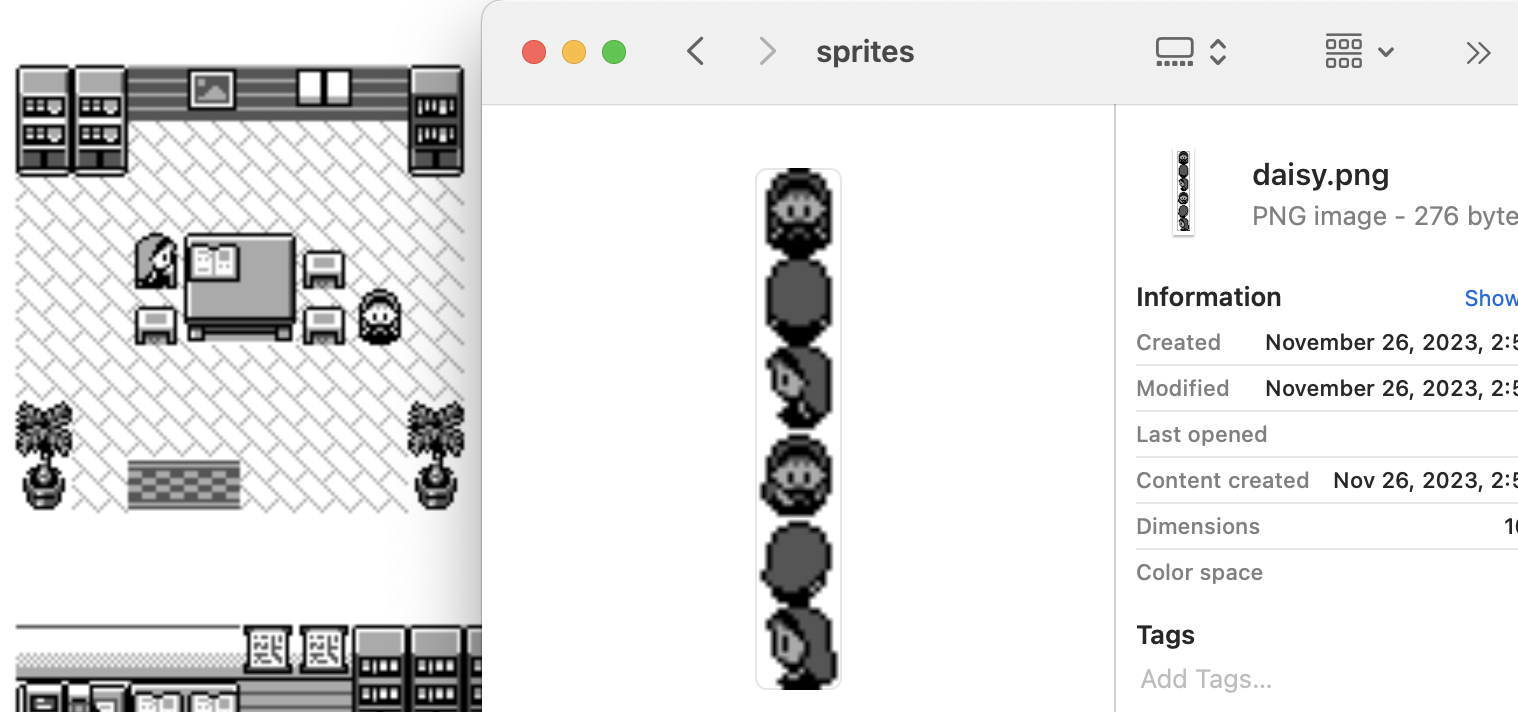
If it was as simple, I would have not written a section on it but there were two complications.
The first one was around colors. For a mysterious reason, they didn't generate PNG with transparency, but instead used white for the transparent color. But you can notice that the face of that person should be rendered as pure white. What they ended up doing is to remap all the colors from [0-255] to [0-127] and keep white (255) as transparent.
One of the sadness of using the browser for doing this kind of work is that the APIs for image manipulation are extremely verbose. This is what it takes to remap the colors and handle transparency:
const image = document.createElement("img"); image.crossOrigin = "Anonymous"; image.onload = () => { const canvas = document.createElement("canvas"); canvas.width = image.width; canvas.height = image.height; const context = canvas.getContext("2d"); context.drawImage(image, 0, 0); const imageData = context.getImageData(0, 0, canvas.width, canvas.height); for (let i = 0; i < canvas.width; ++i) { for (let j = 0; j < canvas.height; ++j) { const offset = (i * canvas.height + j) * 4; if ( imageData.data[offset] === 255 && imageData.data[offset + 1] === 255 && imageData.data[offset + 2] === 255 ) { imageData.data[offset + 3] = 0; } else { imageData.data[offset + 0] *= 2; imageData.data[offset + 1] *= 2; imageData.data[offset + 2] *= 2; imageData.data[offset + 3] = 255; } } } context.putImageData(imageData, 0, 0); spriteImages[capitalSpriteName] = canvas; cb(); }; image.src = gfx_sprites[data_sprites[capitalSpriteName].name]; |
The other problem is that for saving space, only the drawing of the character looking left is stored. In order to render the one looking right, you need to swap the image. I could go and write code to swap each pixel individually but you can also use the transform properties translate and scale of the canvas element to make it easier.
const newCanvas = document.createElement("canvas"); newCanvas.width = spriteImage.width; newCanvas.height = spriteImage.height; const newContext = newCanvas.getContext("2d"); newContext.translate(newCanvas.width, 0); newContext.scale(-1, 1); newContext.drawImage(spriteImage, 0, 0); spriteImage = newCanvas; |
And, we now have life in our world! We now render all the characters and the three initial pokeballs to chose from.
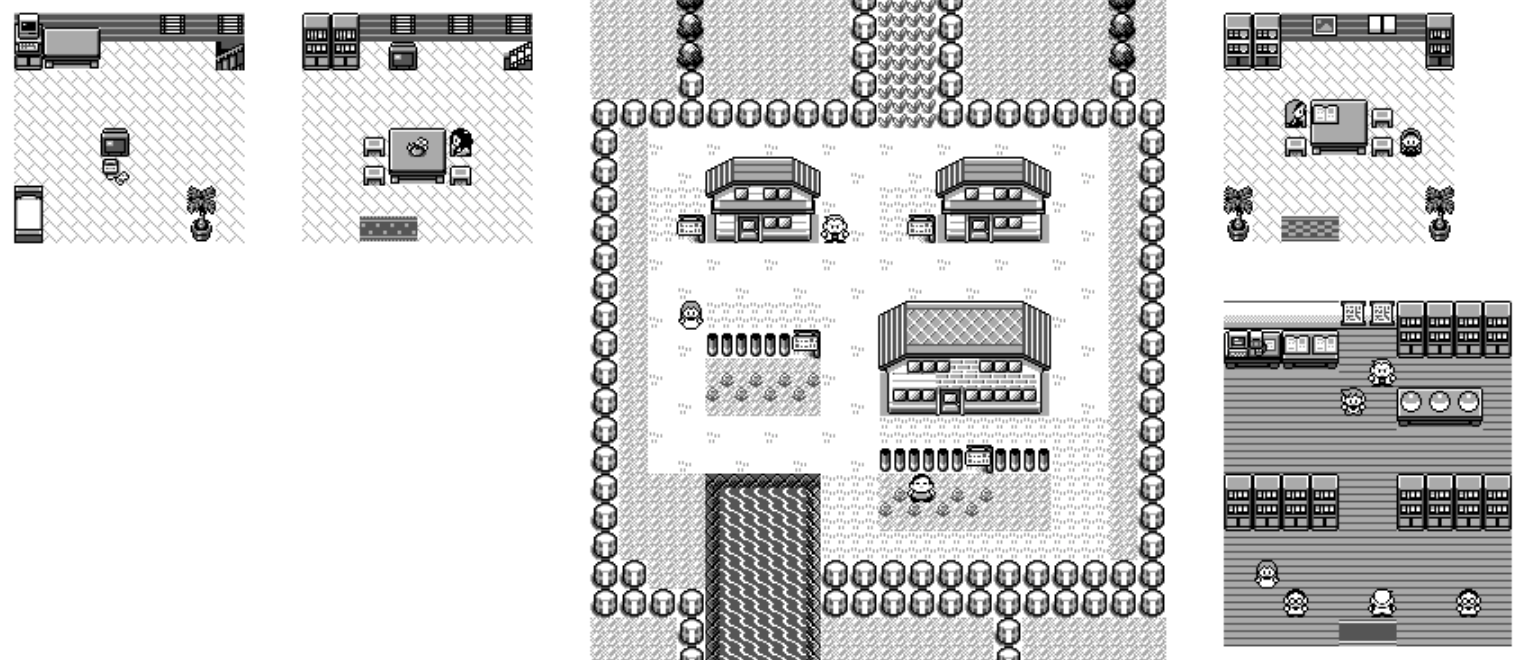
All the maps have a descriptive name. I figured that I would display them in the top left. I could have used the images for the text but I decided to be lazy and use the PKMN RGBY font instead.
It worked great except for maps in the overworld, where it would be drawn on-top of the map connected on-top and not be legible. For this, I used a trick to render the same text many time, first in white to do the outline with a small displacement each time and finally in black.
The code for this is pretty neat:
context.font = "9px PKMN"; context.fillStyle = "white"; for (let p of [ [-1, -1], [-1, 0], [-1, 1], [0, -1], [0, 0], [0, 1], [1, -1], [1, 0], [1, 1], ]) { context.fillText( drawCall.name, drawCall.x + p[0], drawCall.y + p[1] ); } context.fillStyle = "black"; context.fillText( drawCall.name, drawCall.x + leftAdjustment, drawCall.y + topAdjustment ); |
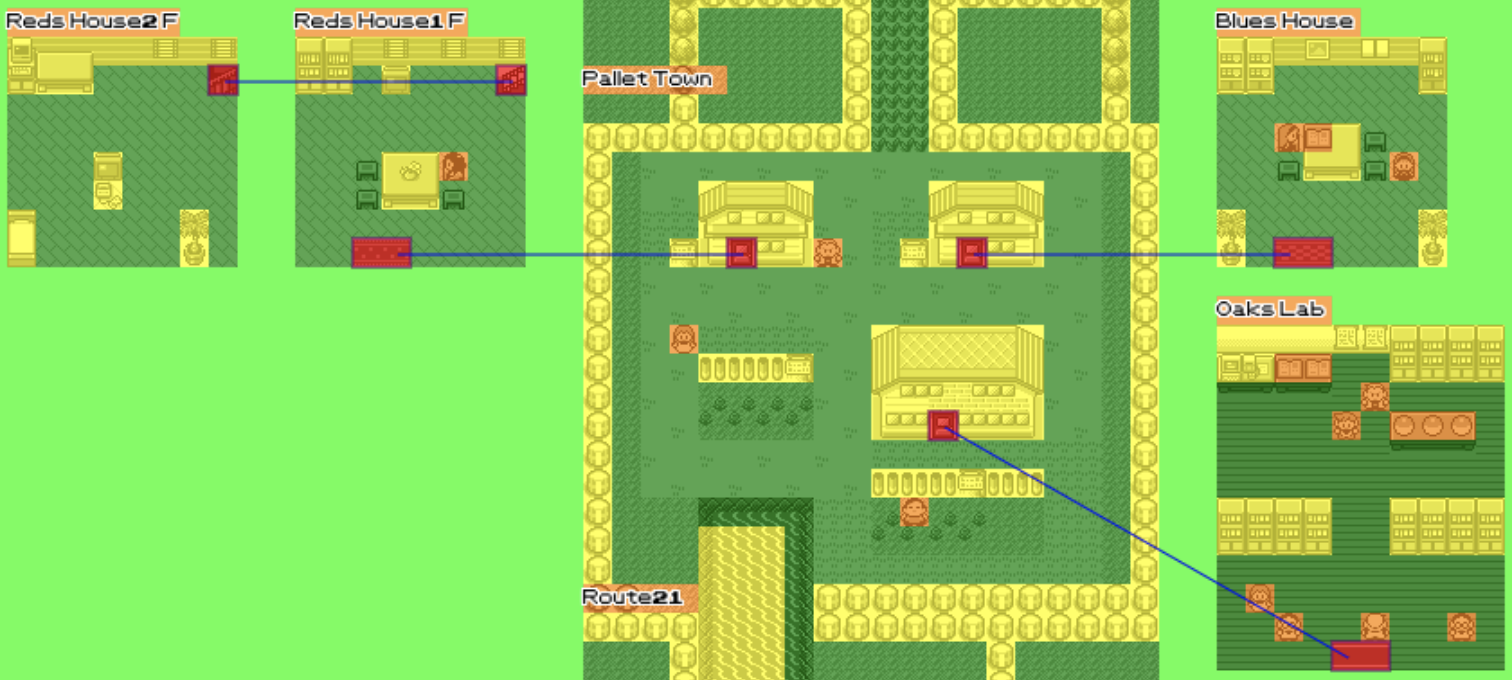
While we display all the maps you can go to, it's not very clear how maps are connected.
In practice, we have a lot of data to deal with: we have a connection from the door to one of the square of the mat. And then each square of the mat is connected to the door. So that's 3 arrows we could draw for each of the connections.
The first step we need to do is to simplify this and group warp zones together and instead of having two directions, only store one between two zones. When there are multiple choices, we draw between the two closest points from the two groups.
I wasn't really satisfied with the way those lines where drawn. Pokemon is all about grids but those diagonal lines break the immersion. I also wasn't happy about the lines going over objects in the world. For example between the two floors of Red's house, you can see the line going through the TV.
The main idea is to use a shortest path algorithm to go from the two ends of the connection. We only let it move in horizontal and vertical steps. And each tile has a different cost. The whitespace around the maps is very cheap, the tiles walkable in-game cost a bit more. At the other end we want to avoid lines crossing over map names, sprites and warp points.
If we draw the same scene with the costs attached to various tiles we get the following:
const COST_WARP = 10; const COST_SPRITE = 4; const COST_MAP_NAME = 2.0; const COST_ARROW = 1.9; const COST_MAP = 1.2; const COST_MAP_WALKABLE = 0.6; const COST_VOID = 0.5; const COST_TURN_MALUS = 0.2; |
The next step is to use A* shortest path algorithm in order to find where to draw the lines. I highlighted all the tiles that the algorithm visited trying to find the shortest path.
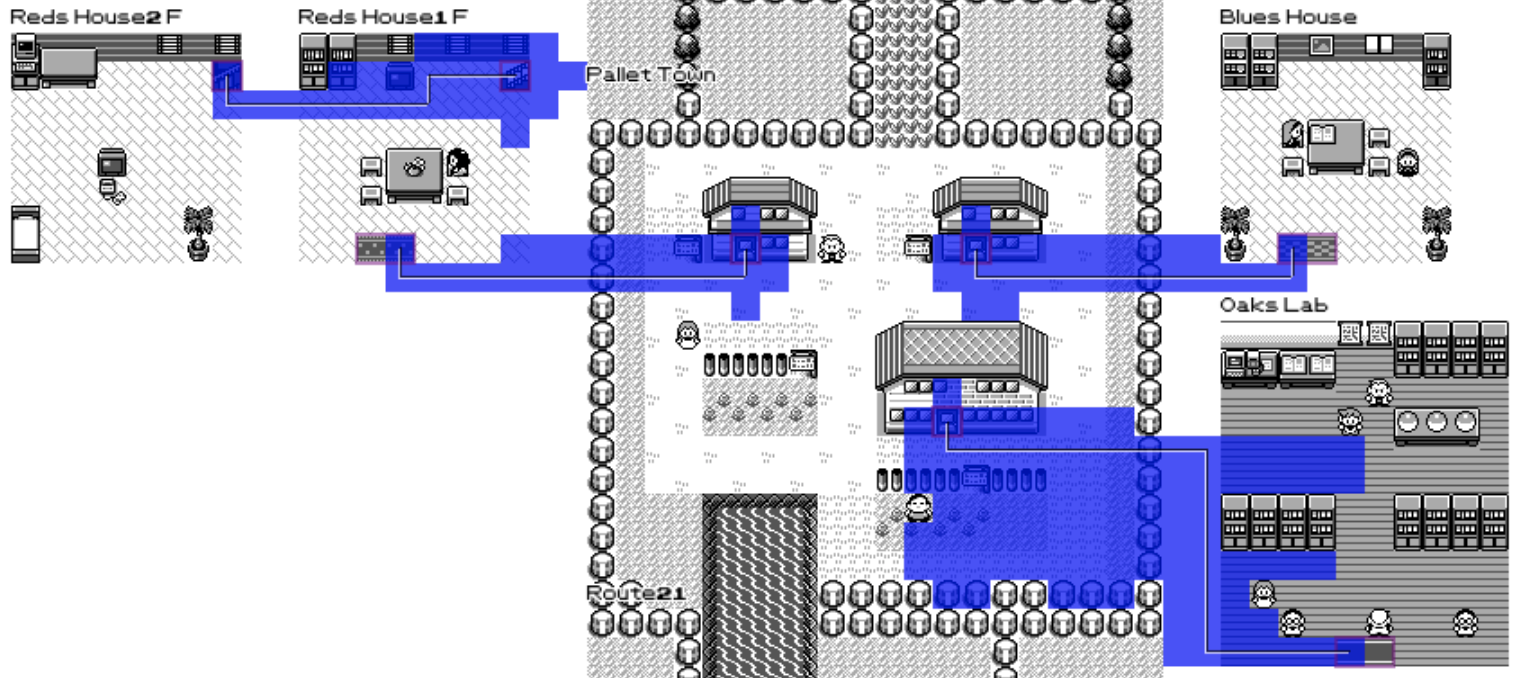
And, we got ourselves lines that I'm happy with!
The A* algorithm is a bit too verbose to print here but you can look at the source code if you're interested in reading it.
The process of building the map from there on was to look through every part of the map, writing down what felt suboptimal, fixing it and repeat until everything looks just great. Here are some of the things I've had to do:
I always forget where hidden items are located, so I draw semi-transparent pokeballs at their locations, both for normal items and game corner coins.
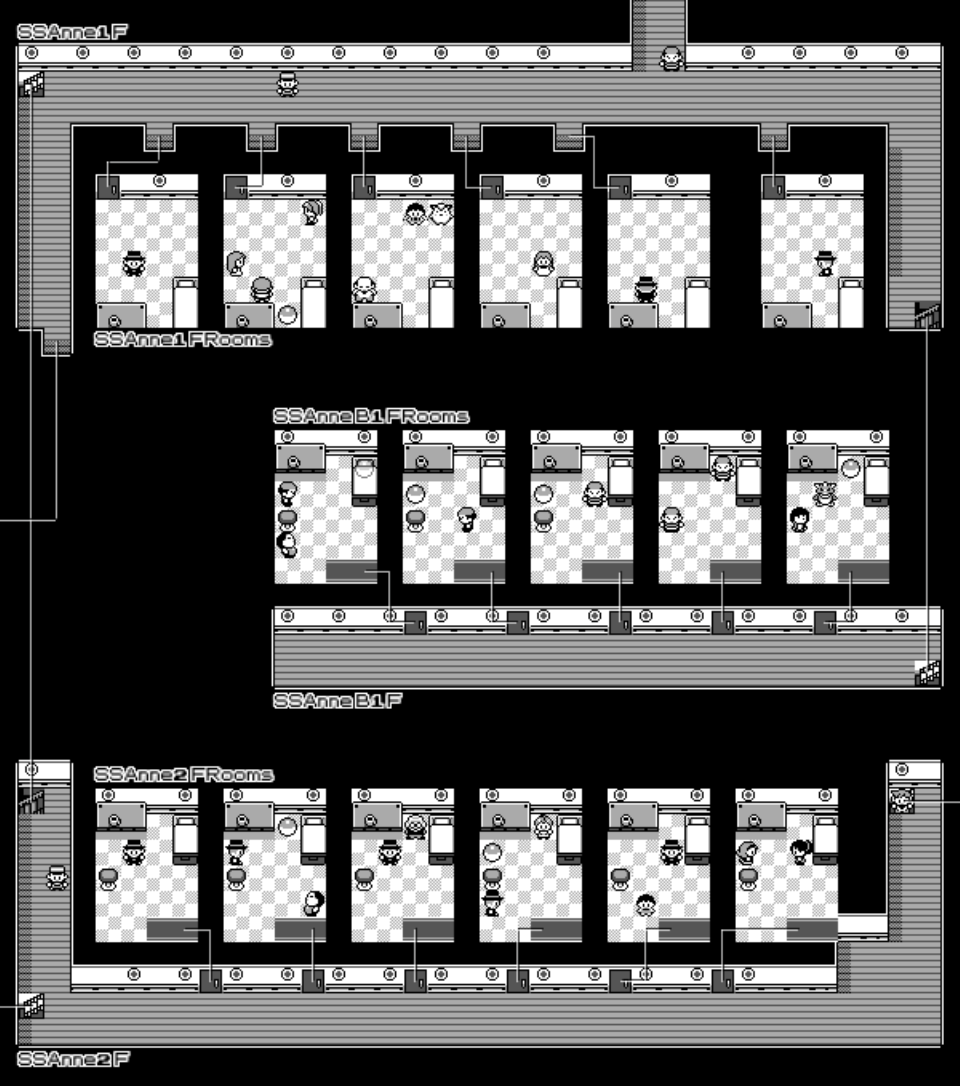
The SS Anne rooms are all separated into different maps. I spent time splitting each section of the map (which requires adjusting coordinates for the tiles to be rendered, warp zones for the connections, sprites and map name) and putting them in their corresponding location on the ship.
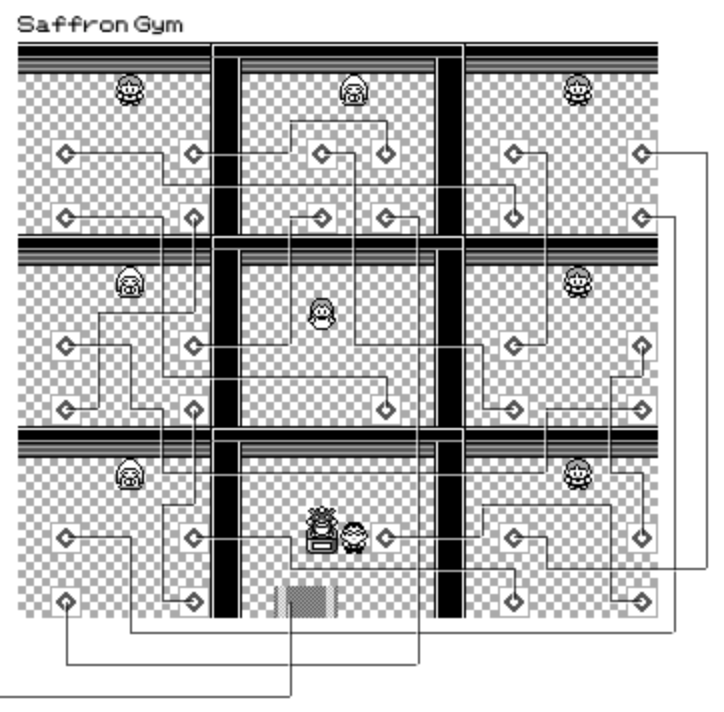
Sabrina's gym puzzle where each section has 4 teleports was really tricky. Thankfully, with a lot of trial and error with the layout algorithm it's possible to find a way to draw lines that do not overlap and don't go on-top of any trainers!
Probably my biggest disappointment doing this project is that Safari Zone is actually not physically sound. It's not possible to layout all the zones in a way that the arrows line up properly. No wonders why I always get so confused as to how to find my way through.
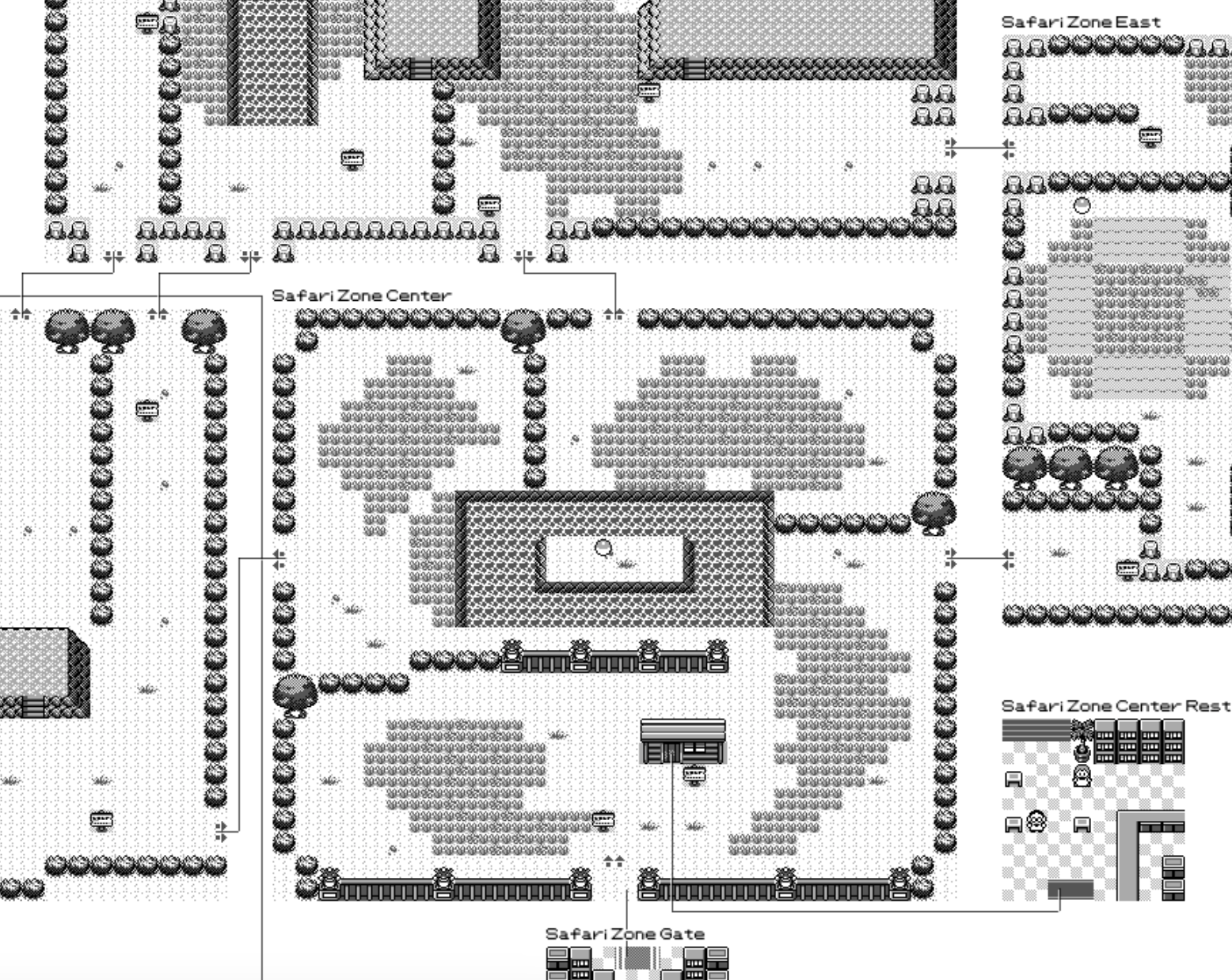
This was a really fun project, it combined my passion for video games and especially Pokemon and my love of programming. I'm planning to print a large version and hang it on my wall somewhere 🙂
You can view the source code and run it yourself on CodeSandbox. I highly recommend CodeSandbox if you want to play around with idea, it removes all the hassle of getting started and configuring your development environment.
Let me know if you spot things that could be displayed better or if you have ideas related to the project. One thing that'd be pretty cool is to make the map interactive, where you can mouse over some grass and it'll tell you what pokemons can spawn and their rates or on a trainer to see their voice lines and what pokemons they battle with.