One common pattern when implementing user interface optimizations is to compute some value for a node where the computation involves looking at neighbor nodes and want to keep this value updated when the tree is mutated.
On this article, I'm going to explain the pattern we implement to solve this use case on various places in React Native.
Example: background color propagation
On React Native, we implement an optimization where the background color is propagated from the parent instead of being transparent. This provides a guarantee to the GPU that it won't need to paint pixels that are underneath. You can read this release notes for a more complete explanation.
In any case, the algorithm is pretty simple, if the background color is not set on an element, we take the one from the nearest parent that has one set. Here's an example:
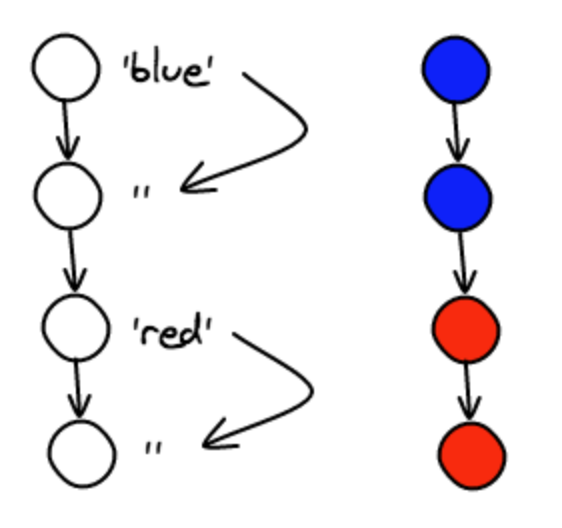
Now, let say that the red node background color is being unset, the example would look like:
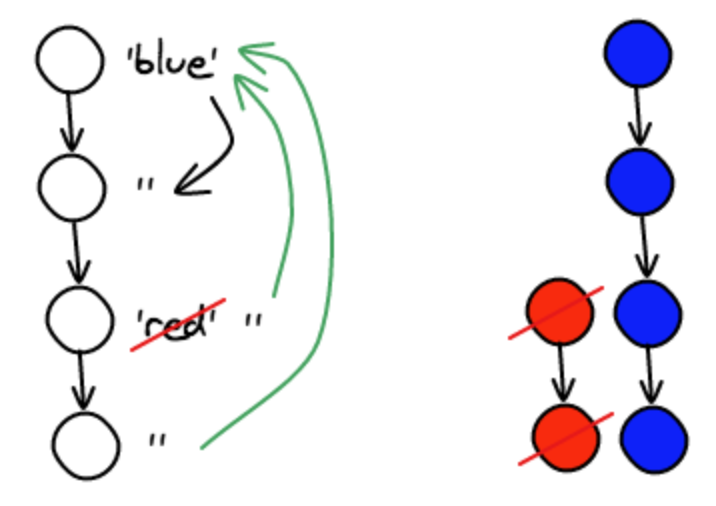
In order to implement this behavior, we first need to traverse up the hierarchy and find the background color and then down to propagate it, but stop at nodes that have set background colors. This means that we have to implement two different algorithms: one for the initial rendering and one for the update.
The complexity of this example as explained is small enough that it is easy to maintain the same invariants. But in practice, this algorithm is a bit more complex: we don't forward the color for transparent nodes nor for the image component in certain cases... We also experimented with more conditions that we didn't end up using.
Dirty-up and execute top-down
What would be great is to just write the top-down recursive algorithm you learn in school to apply colors however you want and whenever there's a mutation just re-run it on the entire tree. The problem with that approach is that you're going to spend a lot of CPU time running this algorithm on the entire tree when you only need to update a few nodes.
Instead, you can dirty the node you are mutating and all the nodes up to the root.
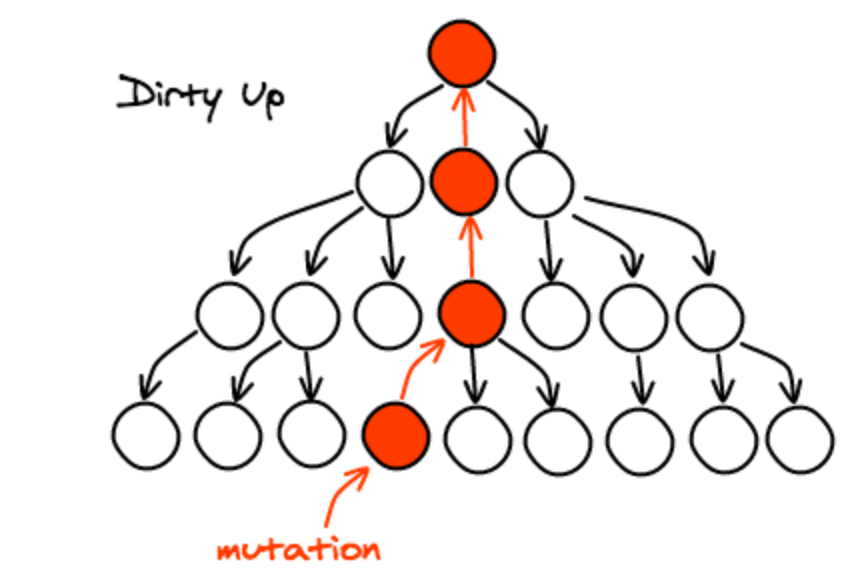
Then, run your algorithm top-down starting at the root.
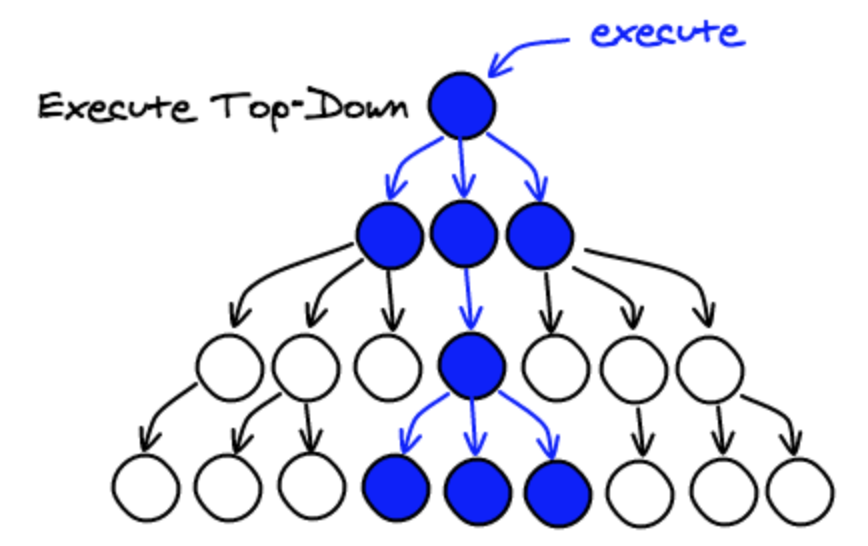
You need to implement a way to figure out if a non-dirty node needs to be recomputed. The strategy we use is to cache all the arguments of getColor, for example (parentColor, nodeColor, isNodeText, ...) along with the result. If we're being called with the same arguments and the node is not dirty, then we don't need to go further and can just bail. The pseudo code looks like this:
function getColor(isDirty, prevArgs, prevValue, nextArgs) { if (isDirty || prevArgs !== nextArgs) { return realGetColorRecursive(...nextArgs); } return prevValue; } |
Conclusion
The benefits of this technique is that you can write your business logic once in a traditional top-down recursive way. You don't need to care about the much harder update case.
The downside is that you are doing more work: instead of touching only the elements that have changed, you need to traverse everything up from the root.
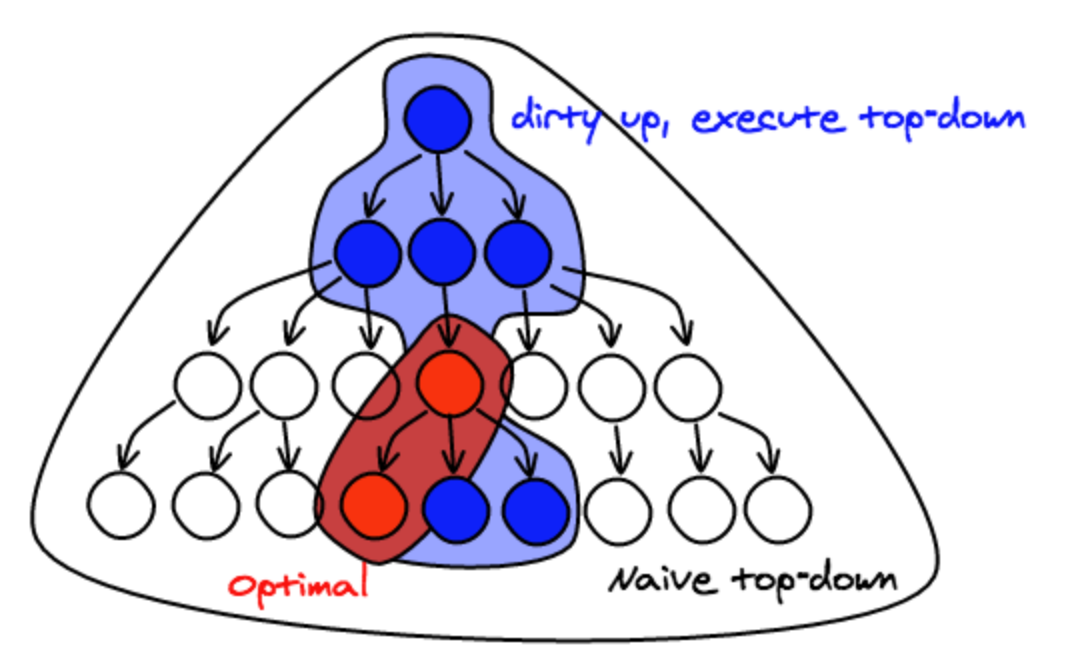
Another downside is that it requires more infrastructure as you need to add a caching layer and refactor your code to add a pass that starts at the top.
We're making use of this technique for a few aspects of React Native:
- Background color is propagation as explained in this article.
- Computing the layout (top, left, width, height) values based on the css attributes (eg marginTop, flex: 1...).
- Flag if a text node is the root of the tree of text nodes to be able to flatten it into a single native view.
- Flag if a node only affect layout and doesn't paint anything so that it can safely be removed from the UI tree.
