In Facebook image layout algorithm, we use square viewport to display the images. Since images are not usually square, we have an issue to solve.
Contain Cover
There are two possible ways to deal with it. You make the image fit entirely in the viewport and add black borders (think about viewing 4/3 movies in a wide screen). Or you can make the viewport fit entirely in the image. Instead of having black bars, you are going to remove some parts of the image.
In CSS, the names for those two concepts are implemented with background-size property that has two values: contain and cover.
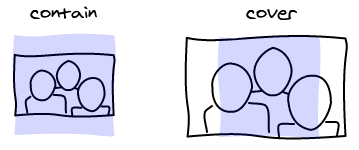
In our case, we display images in a grid. The cover version works best because the images align nicely in the grid. It makes the edges much more visible that gives a structure to the page.

Set up the problem
The choice we made raises another issue: we are no longer displaying the entire photo but only a subset of it. Therefore we have to know what parts of the image we want to keep, and what parts we want to hide.
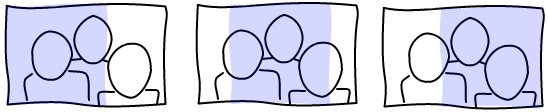
The first thing to notice, is that there is only one degree of freedom. You can either pan the image horizontally or vertically depending on the aspect ratio of the image and viewport.
In order to make that decision, we need to have an idea of what is important in the image. Thankfully, at Facebook, people can tag the images and tell us where the people and other point of interests are. We also know that people are important so we also use detected faces. In the future we could automatically find more such as text, animals ...
Now we have a clearer view of the inputs. We have a set of point of interests aligned in one dimension. We also have a window that we can slide on this dimension. Here's an example:
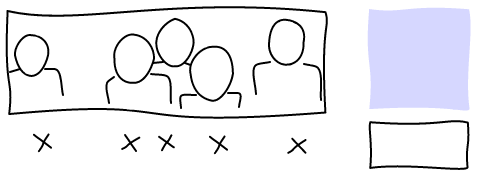
Find maximal window
The idea of the algorithm is to find the position of the window that maximizes the number of point of interests it contains.
A window can be defined only by its starting position since its width is constant. This makes the search space to be the number of pixels in a column/line of the image (minus the size of the window as it must not go outside). Then for each position, you have to compute how many points are inside.
A naive implementation is going to be in the order of O(p * n) where p is the number of pixels and n the number of point of interests. For a typical image with people this means 960 * 3 = 2880 checks. This is way too costly because the number of pixels is an order of magnitude higher than the number of point of interests.
We want to approach the problem the starting from the point of interests. A window can contain, or not, a point of interest. Two windows next to each other that contain the same point of interests can be considered equivalent. With this definition, we can find all the windows much quicker.
We are going to iterate on all the point of interests and consider that they are in the left-most edge of the window. This is the boundary between it between inside and outside of the window. We compute how many points are in that window and keep it if it's bigger than what we had before.
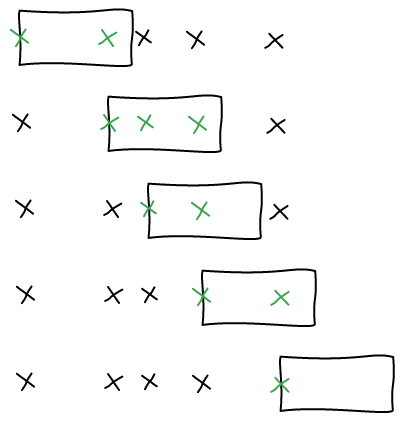
In order to implement this effectively, we can iterate on all the point of interests in O(n). Using binary search, we find the right-most point in O(log(n)), if the points of interests are sorted. It's a O(n * log(n)) to sort them at the beginning.
The total complexity is therefore O(n * log(n)), where n is the number of point of interests. Since most of our images have less than 10 point of interests, our algorithm is essentially free.
Center the window
With a window aligned on the left element, we can balance the right padding equally across left and right to center the window.
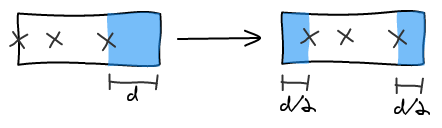
The previous algorithm can return multiple windows that have the same number of points of interest. In this case, we use the window that has the bigger amount of padding. This ensures that heads are less likely to be cut-off in half.
Force someone inside
When you are viewing all the photos someone is tagged in, you would like to make sure that the person isn't being cropped out by the algorithm. Previously, what was done was to center the image on that person. We could instead keep using the current algorithm but force the person in.
Again, we are going to look at the boundaries. The person can be from the left edge to the right one. So we are going to place the person at the left and right of the viewport and remove all the points that cannot be in the same screen.
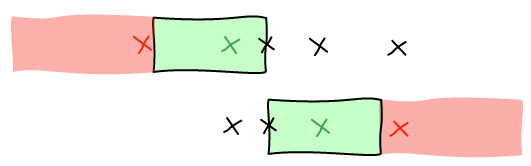
Then, we have the guarantee that all the sets of points we are going to chose also contain the person. We run the algorithm again with that limited set of points to find the window.
Conclusion
The current heuristic is to have images horizontally centered and vertically centered at the first third of the photo, where most faces at. Those are empiric values that work surprisingly well. Also, most images are 4:3, therefore cropping to a 1:1 ratio removes 25% of the photo total, which is only 12.5% on each side.
In order to test the algorithm, we use more extreme viewports. A quick run on my photos and some friends photos shows that it either leaves the crop as is or improves it. It is going to be interesting to test it on Facebook views.

