For a school project, I had to make a part of a spell-check program. Given a dictionnary of words, you have to determine all the words that are within K mistakes of the original word.
Trie
As input, we've got a list of words along with their frequency. For example, with the following list, we are going to build a trie.
do 100 000 dont 15 000 done 5 000 donald 400 |
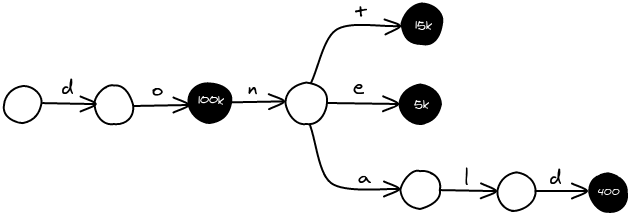
In order to minimize the memory footprint, I've made a node structure that fits into 32 bits.
struct { unsigned short is_link : 1; unsigned short is_last_child : 1; union content { struct { unsigned short letter : 6; // 2^6 = 64 different charaters unsigned int next : 24; // 2^24 = 16 777 216 nodes } link; struct { unsigned short is_overflow : 1; unsigned int freq : 29; // 2^29 = 536 870 912 } final; } } node; |
The frequence can be greater than 2^30. We're going to store values between 0 and 2^29 directly inside the node, and if it doesn't fit, we are going to retrieve the value in a separate memory location and store its corresponding id.
Damerau Levenshtein Distance
The distance between two words we use is Damerau Levenshtein. In order to calculate the distance, we compute the following table.
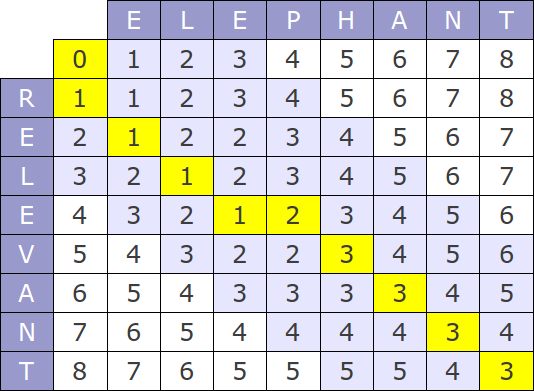
Where each slot D(i,j) is calculated using the following formula:

There are two things to tweak in order to use this distance with a trie.
Incremental computation
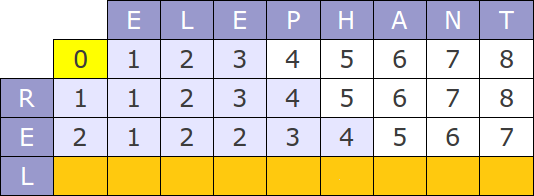
Obviously, we are not going to recompute the whole distance for each node. We can use one table for the whole search. For each node you explore, you are going to compute only the line corresponding to it's depth in the tree. For example, if you look for elephant and are currently at rel in the tree, you are only going to compute the 3rd row. The first two rows r and e are correct.
When to stop?
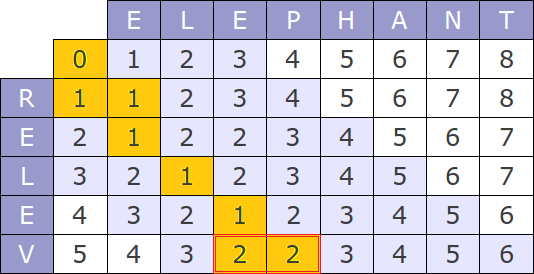
Now we need to find given a current table, when to stop. For example, if we search for elephant with 1 error and we are at zz, we can stop, there won't be any word that satisfy the request. I've found out that if the minimum value of the current row is bigger than the number of tolerated errors, we can stop the search. When searching for elephant with 1 error, we stop at the 4th row (rele) because the minimum is 2.
Heuristics
When we traverse the trie in a fuzzy way, we explore a lot of useless nodes. For example, when we fuzzy search for eve, we are going to explore the beginning of the word evening. Let's see some strategies to reduce the amount of nodes we explore.
Different trie per word length
Fuzzy search for the 5-letter word like happy with 1 error, you know that your results are going to be words of length 4, 5 or 6. In a generalized way, you are only going to look for words in the range [len - error; len + error]. You can create a trie for each length. Then you search in all the required tries and aggregate the results.
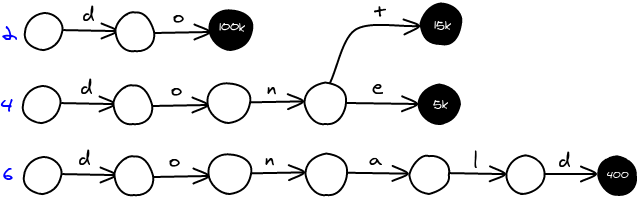
The downside with this approach is that you lose the high prefix compression of the trie.
Word length
Instead of making on trie per word length, you can encode the word lengths directly in the nodes. Each node is going to have a bitfield containing the lengths of the words in the sub-tree. For example in the example above, the first node leads to words of size 2, 4 and 6, therefore the field will have 0b010101....
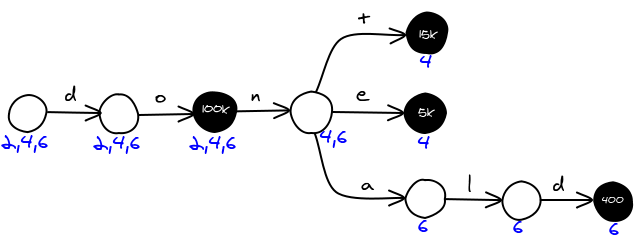
If you are looking for a word of size 5 with 1 error, you are going to create a bitfield of word lengths you are interested in 0b000111.... For each node, you and both bitfields, if the result is not 0, then you've got a potential match.
Conclusion
In order to test for performance we search every word at a distance 2 of the 400 most popular english words. The dictionnary contains 3 millions words. It takes 22 seconds on my old 2Ghz server to run it. It takes an average of 55ms per fuzzy search and generates an average of 247 results.
Felix Abecassis, a friend of mine spent time working on parallelizing the search with Intel TBB. You might want to read it in order to improve by a factor your performance 🙂
Since it's a competitive school project, I'm not going to give the source publicly. Please ask them if you are interested 🙂
