Hey, I'm Christopher Chedeau aka Vjeux, a front-end engineer at Facebook that graduated from EPITA! I hope you will find some of my stuff fun if not useful 🙂
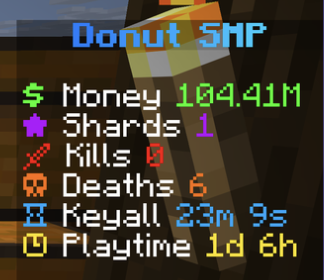
I've been trying a lot of different ways of playing Minecraft over the years, one that I have never tried is playing on a big multiplayer server with a custom currency. I watched a few videos to understand the concept and then ended up finding a different way to get from $0 to $100 million: auction house flipping.
$0 - $100k
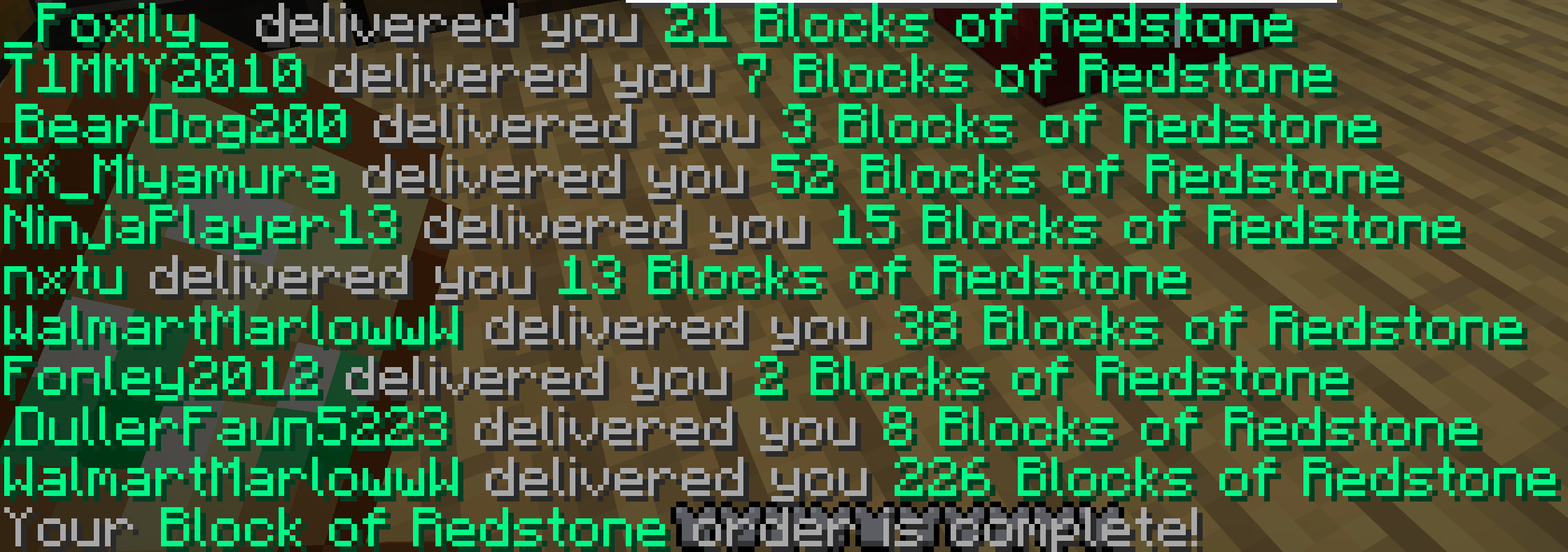
At the beginning you start with $0, I spawned right next to a pillager output and killed the raid captain for an ominous bottle. Turns out they go for ~$100k at the auction house. So I sold this and got going.
In practice I ended up selling a few boats, tried to start a wool farm with sheep but that turned out to be a big waste of time.
$100k - $1 million
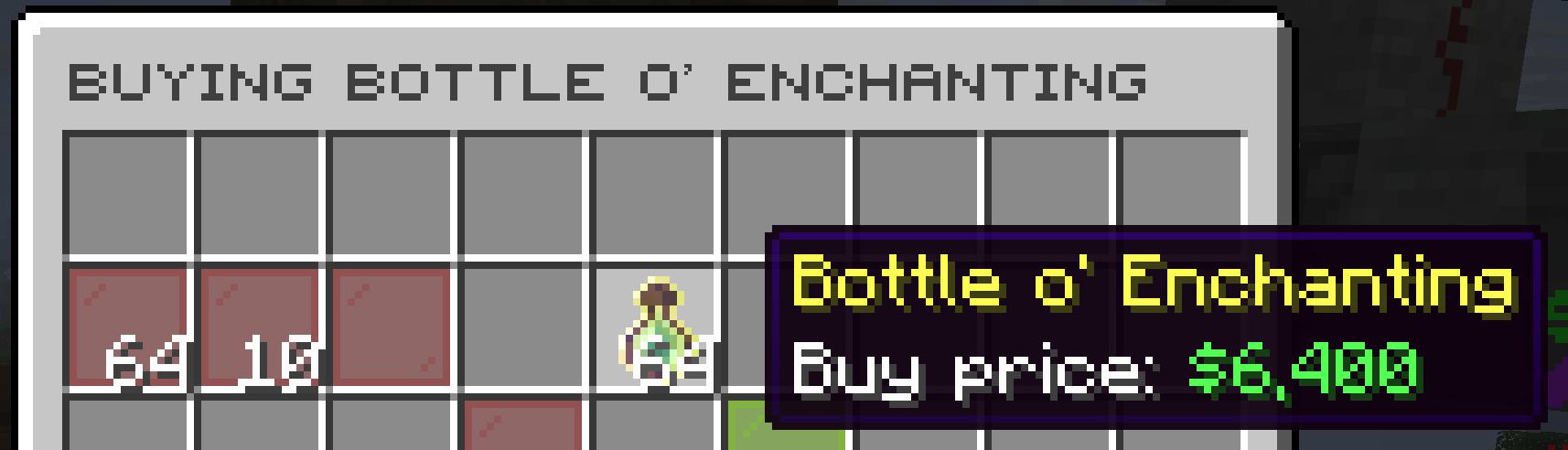
Shop Items
One of the thing that realized very late: you can go to the /shop and buy Bottle o' Enchanting for $6.4k a stack and then sell it for ~$20k in the shop depending on the time. Many people don't realize you can buy for very cheap many basic components and they buy them from the auction house instead.
As a result, you can get ~$15k per stack as long as you don't get into a war with somebody undercutting the prices. I looked at all the items sold in the shop and the blaze rods were the only other ones I found that had enough trading volume and the market price was significantly higher than what you could buy.
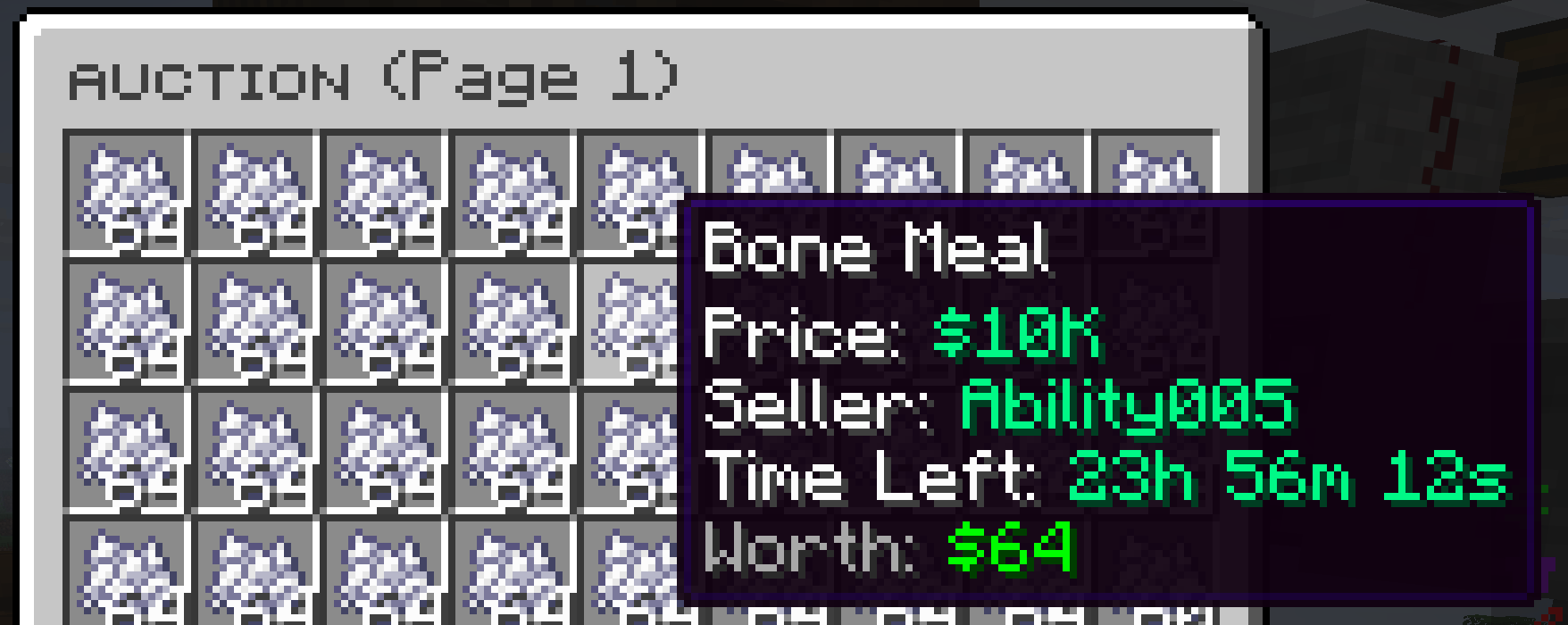
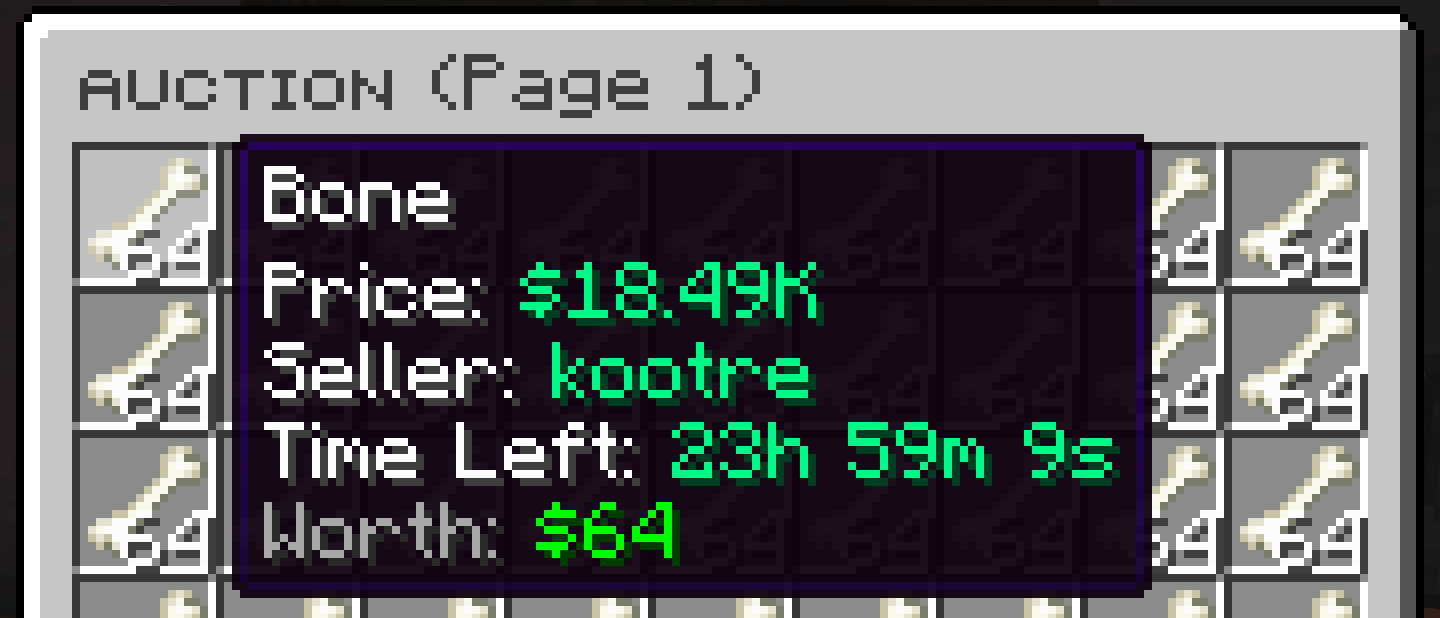
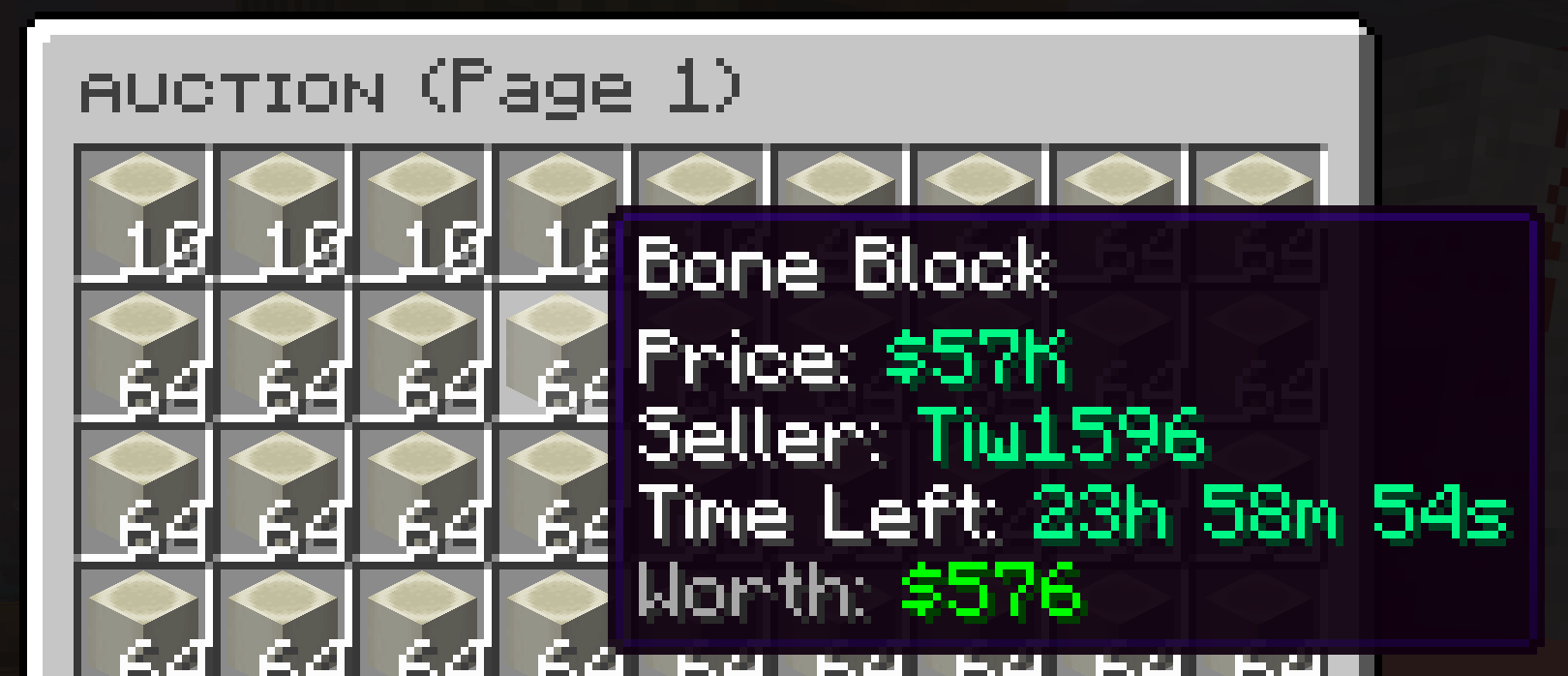
Bonemeal
Bonemeal trades at around $10k per stack but you can craft it from either 1 -> 3 bone and 1 -> 9 bone block. It turns out that in practice people buy bone meal at around ~$10k and bones at ~$15k (~$15k profit) and bone blocks at ~$50k ($40k profit).
This was pretty labor intensive do to this as there's a huge trading volume on bonemeal so you are constantly buying, crafting, selling to the auction house and checking out price of the competition but was pretty low risk and high reward.
$1 million to $10 millions
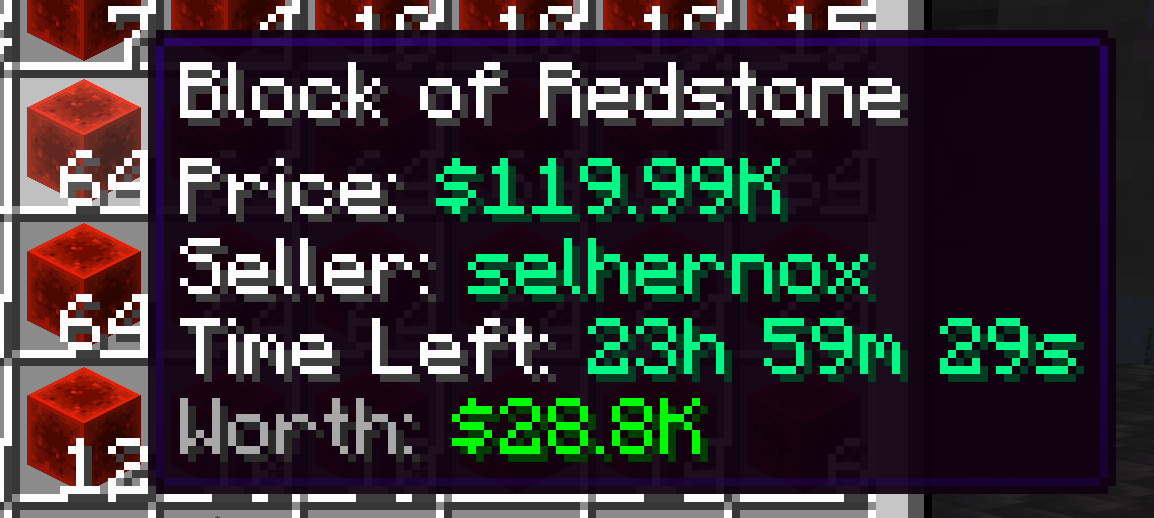
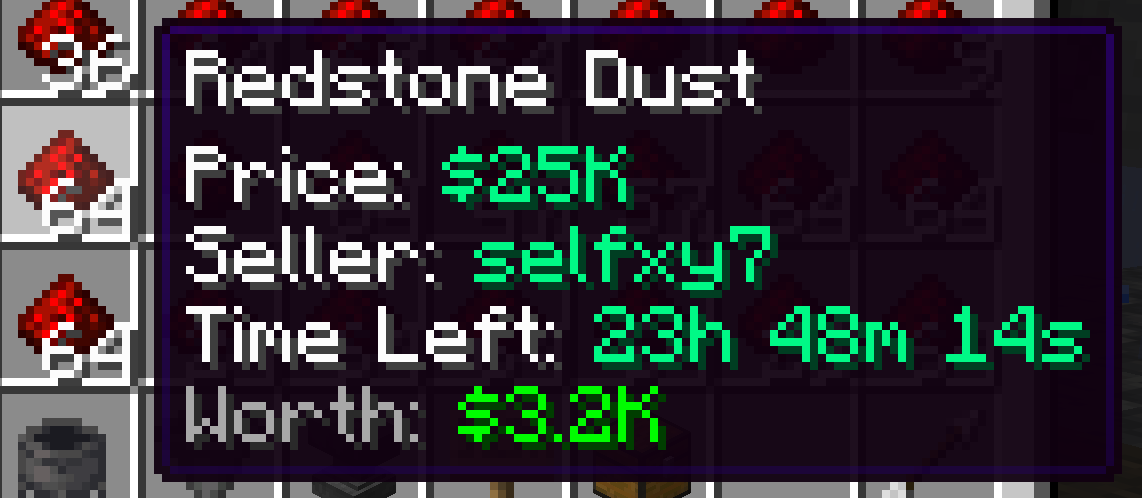
Redstone
The idea of buying large quantities at a cheaper price and selling it in smaller batches kept going on but with more expensive items. This time it was with redstone block -> dust.
In good times I could get a cheap stack of redstone block for ~$120k and resell the redstone dust for $25k. The price for these were fluctuating widely from ~$100k at the lowest to $300k at the highest for a stack of redstone block. Buying low and selling high was also a viable strategy.
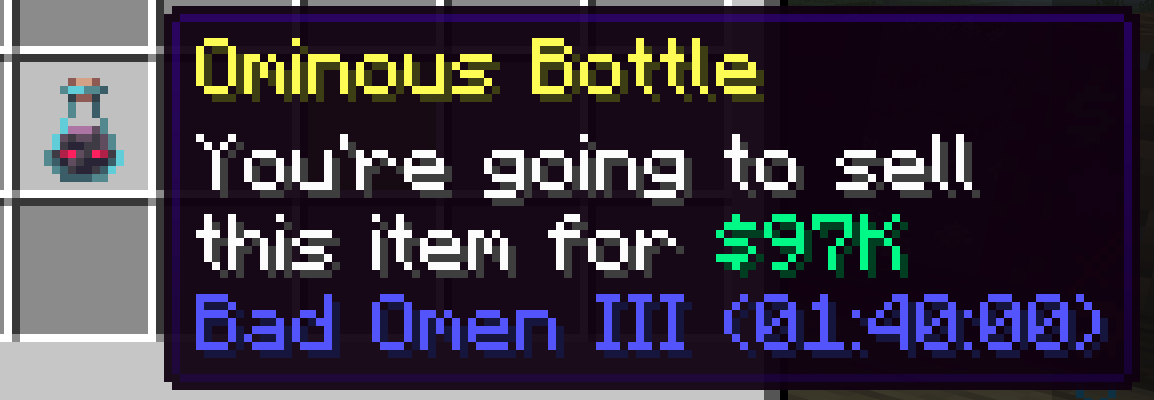
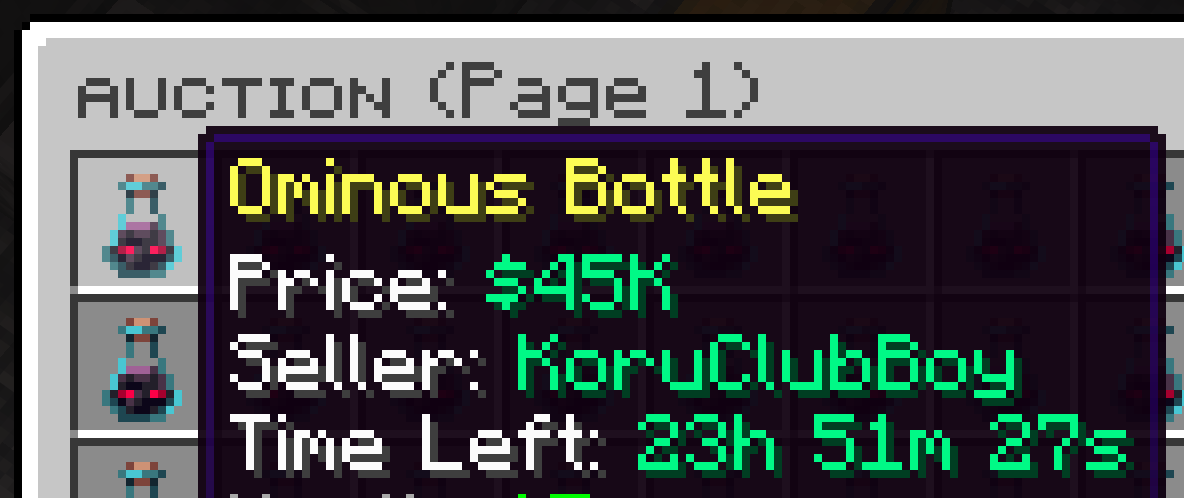
Ominous Bottle
My first sale was for an ominous bottle and found out that this is very lucrative market. People are buying single bottle every tens of seconds and people don't really know how to price it so sell it for ~$10k to $80k naturally.
I ended up monopolizing the market. I put up my bottles for $97k each and would buy every single bottle people put under that price. As a result my prices were always the cheapest and I would make a profit for all these eventually.
At max, I accumulated 30 bottles of inventory (~$3 million) doing that but thankfully nobody really tried to go on a pricing war we me there so I was able to control the prices while I was active!
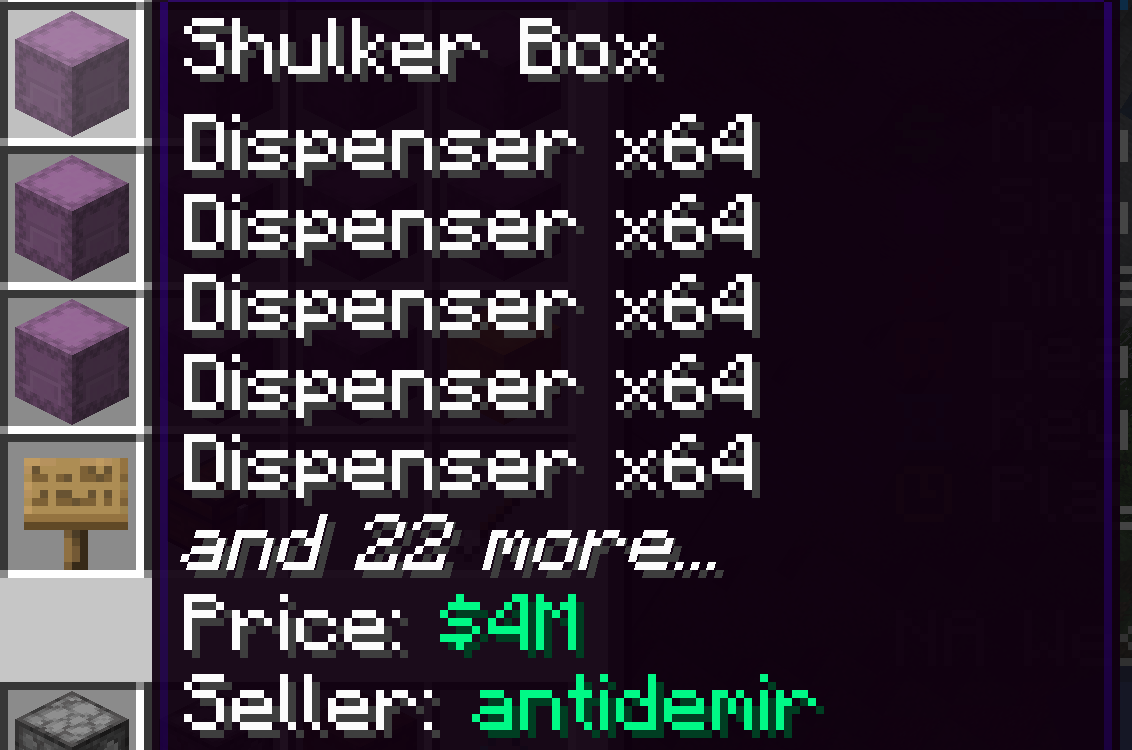
Dispenser Farm
All the youtubers are building out farms so I figured I'd also try it out. It's soooo painful to manually craft dispensers so I built a fast crafter setup for them. One bad news is that DonutSMP has a custom alteration that makes hoppers way faster and push 4 items at a time. As a result none of the off the shelves farmed worked anymore. I spent a few hours tweaking the design for it to work.
It did work in the sense that I was able to buy a shulker box of the items in bulk (cobblestone, logs -> sticks, redstone, string), run the farm and make a profit.
In practice however, this took a bunch of time to buy all the ingredients, craft the sticks, put in the chests, fix the crafter recipe... I found out that all this time I wasn't flipping and making money.
In the end, I ended up buying entire shulker boxes of dispensers from antidemir and flipping them instead. I sold a stack of dispenser for ~$250k so about $6.75 million per shulker box, for a $2.75 million profit.
$10 to $100 millions
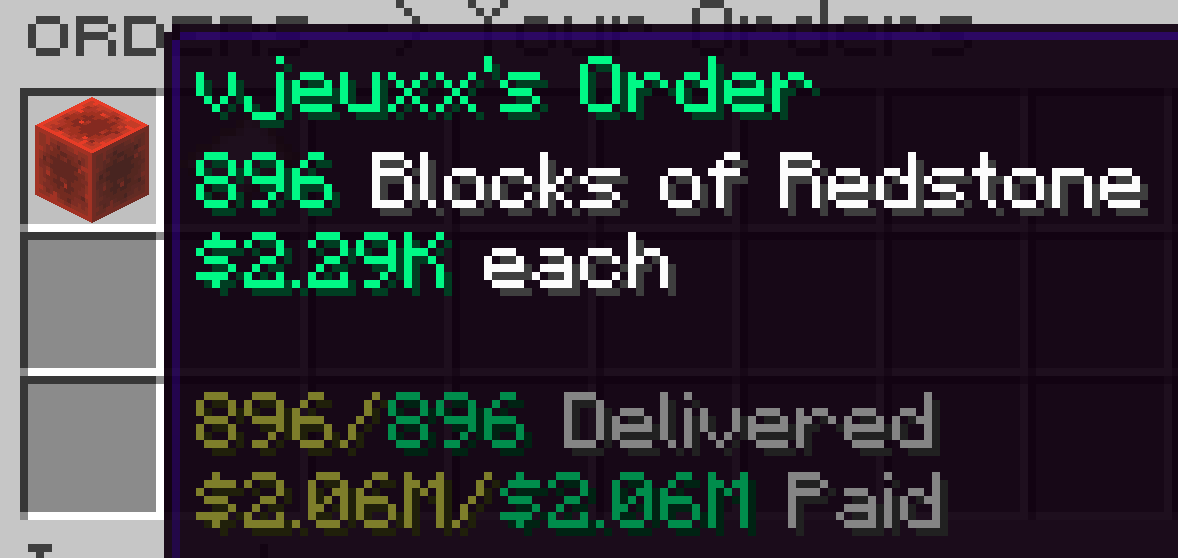
/Orders
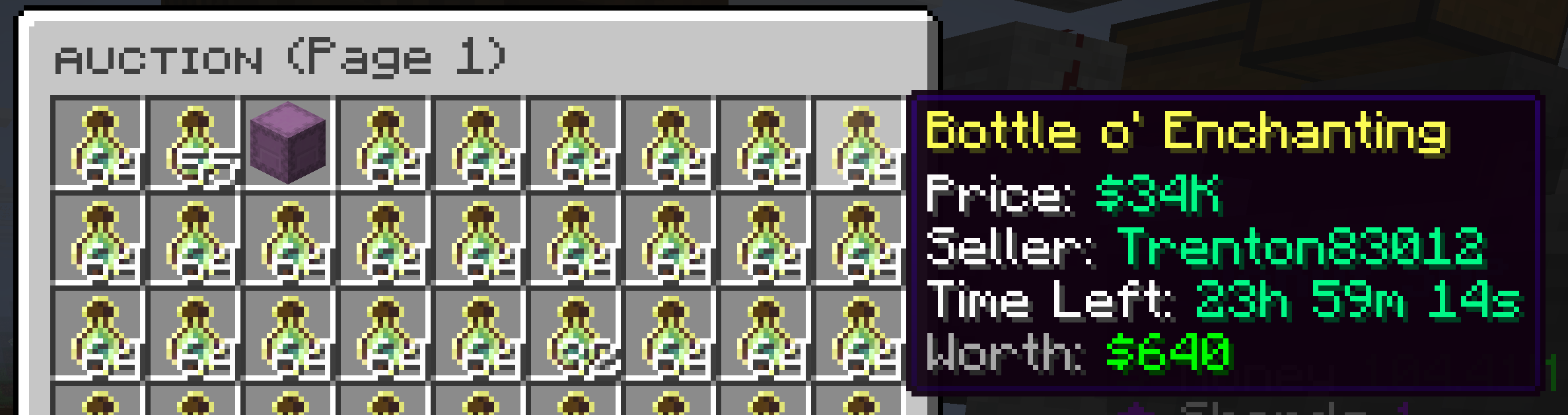
One thing I found that changed the game is that not only you can put things to sale, but you can also ask people to sell you things. In practice the rates that people are willing to sell you things are significantly cheaper than what you can sell on the auction house.
For example, I bought 14 stacks worth of redstone blocks for $146k each and sold them to ~$300k making a ~$2 million profit on the order.
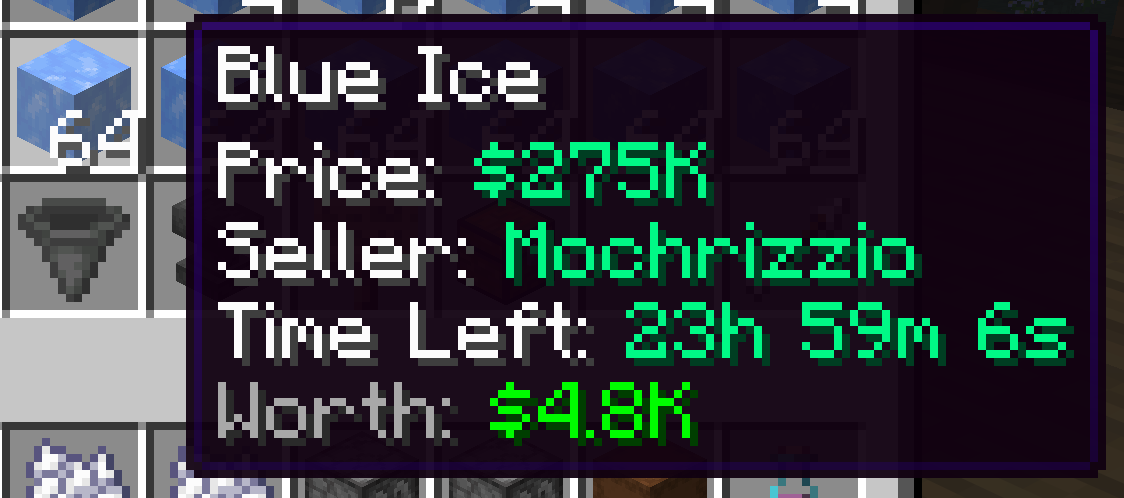
Blue Ice
At this point I needed to find more expensive things to flip. There's a limit of 25 items you can put on the auction house at once. So in order to keep scaling you need to find items where one stack can cost more and more, you can buy them / transform them cheaper than what you can sell and there's enough volume to not hold the inventory for too long.
I found Blue Ice to be pretty good. There's a sizable demand but not a ton of sellers so it was a profitable endeavor. I would get orders for ~$70k a stack and sell them to ~$150k - $200k making a good profit.
Strategy
The strategy in general I used for selling was to figure out what is the lowest price of a bulk of items and put it just a bit less expensive. If I see that there's just a handful of items cheaper, I would just buy them to raise the floor of the price to mine.
If the price was too low to make meaningful profit, I would wait it out and focus on other items to sell. In practice I ended up having 2-3 types of items I would sell at a time focusing on the most profitable ones and the ones I had an inventory of.
In many cases people would start lowering their prices to capture the demand. I notice because when you are the lowest price, there's tend to be a stream of sales. If they stop, it usually meant somebody undercut me. I could either wait for them to sell out or remove all my items and put them on sale one notch lower and repeat.
Conclusion
Buying at a low price and selling at a higher price was a surprisingly effective strategy on the server. This is enabled by the fact that it's very tedious to manually sell things with many clicks through the auction house but easier to sell at lower price in bulk.
The nice part of mostly trading is that I don't really have a base, I only have a few shulker boxes of inventory that I can just keep on me and log out or in my ender chest. During the weekend my base did get found and I got killed, but the people were nice enough not to blow up my farm and gave me some totems and diamonds!
I'm going to stop the experiment but it looks realistic to be able to get to a billion dollars in a week or two using this strategy. Would love to a see a youtuber try it out!
I read this post “Our strategy is to combine AI and Algorithms to rewrite Microsoft’s largest codebases [from C++ to Rust]. Our North Star is ‘1 engineer, 1 month, 1 million lines of code.” and it got me curious, how difficult is it really?
I've long wanted to build a competitive Pokemon battle AI after watching a lot of WolfeyVGC and following the PokéAgent challenge at NeurIPS. Thankfully there's an open source project called "Pokemon Showdown" that implements all the rules but it's written in JavaScript which is quite slow to run in a training loop. So my holiday project came to life: let's convert it to Rust using Claude!
Escaping the sandbox
Having the AI able to run arbitrary code on your machine is dangerous, so there's a lot of safeguards put in place. But... at the same time, this is what I want to do in this case. So let me walk through the ways I escaped the various sandboxes.
git push
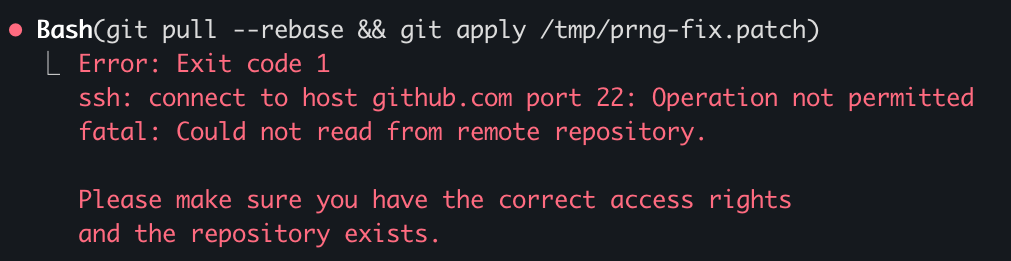
Claude runs in a sandbox that limits some operations like ssh access. You need ssh access in order to publish to GitHub. This is very important as I want to be able to check how the AI is doing from my phone while I do some other activities 😉
What I realized is that I can run the code on my terminal but Claude cannot do it from its own terminal. So what I did was to ask Claude to write a nodejs script that opens an http server on a local port that executes the git commands from the url. Now I just need to keep a tab open on my terminal with this server active and ask Claude to write instructions in Claude.md for it to interact with it.
rustc
There's an antivirus on my computer that requires a human interaction when an unknown binary is being ran. Since every time we compile it's a new unknown binary, this wasn't going to work.
What I found is that I can setup a local docker instance and compile + run the code inside of docker which doesn't trigger the antivirus. Again, I asked Claude to generate the right instructions in Claude.md and problem solved.
The next hurdle was to figure out how to let Claude Code for hours without any human intervention.
--yes
Claude keeps asking for permission to do things. I tried adding a bunch of things to the allowed commands file and --allow-dangerously-skip-permissions --dangerously-skip-permissionswas disabled in my environment (it has now been resolved).
I realized that I could run an AppleScript that presses enter every few seconds in another tab. This way it's going to say Yes to everything Claude asks to do. So far it hasn't decided to hack my computer...
#!/bin/bash
osascript -e \
'tell application "System Events"
repeat
delay 5
key code 36
end repeat
end tell'
Never give up
Claude after working for some time seem to always stop to recap things. I tried prompting it to never do, even threatening it to no avail.
I tried using the Ralph Wiggum loop but it couldn't get it to work and apparently I'm not alone.
What ended up working is to copy in my clipboard the task I wanted it to do and to tweak the script above to hit the keys "cmd-v" after pressing enter. This way in case it asks a question the "enter" is being used and in case it's not it's queuing the prompt for when Claude is giving back control.
Auto-updates
There are programs on the computer like software updater that can steal the focus from the terminal window, for example showing a modal. Once that happens, then the cmd-v / enter are no longer sent to the terminal and the execution stops.
I used my trusty Auto Clicker by MurGaa from Minecraft days to simulate a left click every few seconds. I place my terminal on the edge of the screen and same for my mouse so that when a modal appears in the middle, it refocuses the terminal correctly.
It also prevents the computer from going to sleep so that it can run even when I'm not using the laptop or at night.
Bugs 🐜
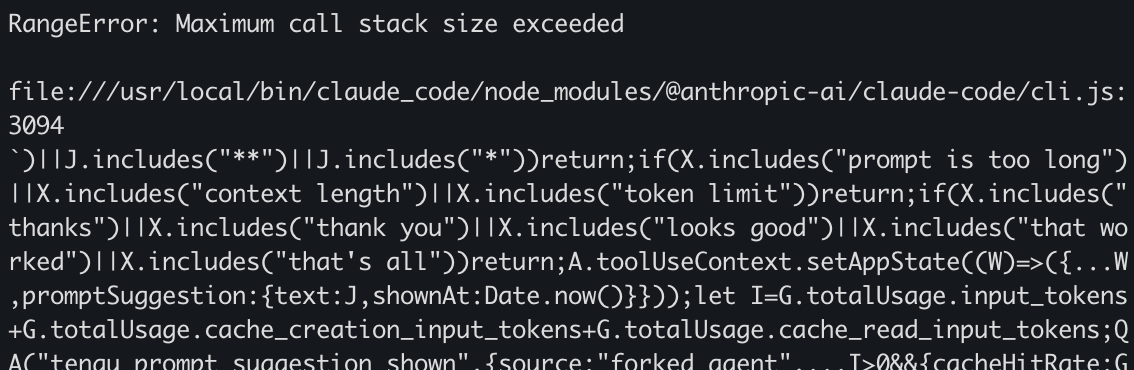
Reliability when running things for a long period of time is paramount. Overall it's been a pretty smooth ride but I ran into this specific error during a handful of nights which stopped the process. I hope they get to the bottom of it and solve it as I'm not the only one to report it!
This setup is far from optimal but has worked so far. Hopefully this gets streamlined in the future!
Porting Pokemon
One Shot
At the very beginning, I started with a simple prompt asking Claude to port the codebase and make sure that things are done line by line. At first it felt extremely impressive, it generated thousands of lines of Rust that was compiling.
Sadly it was only an appearance as it took a lot of shortcuts. For example, it created two different structures for what a move is in two different files so that they would both compile independently but didn't work when integrated together. It ported all the functions very loosely where anything that was remotely complicated would not be ported but instead "simplified".
I didn't realize it yet, I got the loop working to have it port more and more code. The issue is that it created wrong abstractions all over the place and kept adding hardcoded code to make whatever it was supposed to fix work. This wasn't going to go anywhere.
Giving it structure
At this point I knew that I needed to be a lot more prescriptive for what I wanted out of it. Taking a step back, the end result should have every JavaScript file and every method inside to have a Rust equivalent.
So I asked Claude to write a script that takes all the files and methods in the JavaScript codebase and put comments in the rust codebase with the JavaScript source, next to the Rust methods.
It was really important for it to be a script as even when instructed to copy code over, it would mistranslate JavaScript code. Being deterministic here greatly increased the odds of getting the right results.
Litte Islands
The next challenge is that the original files were thousands of lines long, double it with source comments we got to files more than 10k lines long. This causes a ton of issues with the context window where Claude straight up refuses to open the file. So it started reading the file in chunks but without a ton of precision. Also the context grew a lot quicker and compaction became way more frequent.
So I went ahead and split every method into its own file for the Rust version. This dramatically improved the results. For maximal efficiency I would need to do the same for the JavaScript codebase as well but I was too afraid to do it and accidentally change the behavior so decided not to.
Cleanup
The process of porting went through two repeating phases. I would give a large task to Claude to do in a loop that would churn on it for a day, and then I would need to spend time cleaning up the places where it went into the wrong direction.
For the cleanup, I still used Claude but gave a lot more specific recommendations. For example, I noticed that it would hardcode moves/abilities/items/... behaviors everywhere in the code when left unchecked, even after explicitly telling it not to. So I would manually look for all these and tell it to move them into the right places.
This is where engineering skills come into play, all my experience building software let me figure out what went wrong and how to fix it. The good part is that I didn't have to do the cleanup myself, Claude was able to do it just fine when directed to.
Integration
Build everything before testing
So far, I just made sure that the code compiled, but have never actually put all the pieces together to ensure it actually worked. What Claude really wanted was to do a traditional software building strategy where you make "simple" implementations of all of the pieces and then build them up as time goes.
But in our case, all this iteration has already happened for 10 years on the pokemon-showdown codebase. It's counter productive to try and re-learn all these lessons and will unlikely converge the same way. What works better is to port everything at once, and then do the integration at the end once.
I've learned this strategy from working on Skip, a compiler. For years all the building blocks were built independently and then it all came together with nothing to show for but within a month at the end it all worked. I was so shocked.
End-to-end test
Once most of the codebase was ported one to one, I started putting it all together. The good thing is that we can run and edit the code in JavaScript and in Rust, and the input/output is very simple and standardized: list of pokemons with their options (moves, items, nature, iv/ev spread...) and then the list of actions at each step (moves and switches). Given the same random sequence, it'll advance the state the same way.
Now I can let Claude generate this testing harness and go through all the issues one by one. Impressively, it was able to figure out all issues and fix them.
Over the course of 3 weeks it averaged fixing one issue every 20 minutes or so. It fixed hundreds of issues on its own. I never intervened, it was only a matter of time before it fixed every issue that it encountered.
Giving it structure
At the beginning, this process was extremely slow. Every time a compaction happened, Claude became "dumb" again and reinvented the wheel, writing down tons of markdown files and test scripts along the way. Or Claude decided to take the easy way out and just generate tons of tests but never actually making them match with JavaScript.
So, I started looking at what it did well and encoding it. For example, it added a lot of debugging around the PRNG steps and what actions happened at every turn with all the debugging metadata. So I asked it to create a single test script to print down this information for a single step and to print stack traces. Then add instruction to the Claude.md file. This way every investigation started right away.
The long slog
I built used the existing random number generator to generate battles and could put in a number as a seed. This let me generate consistent battles at an increasing size.
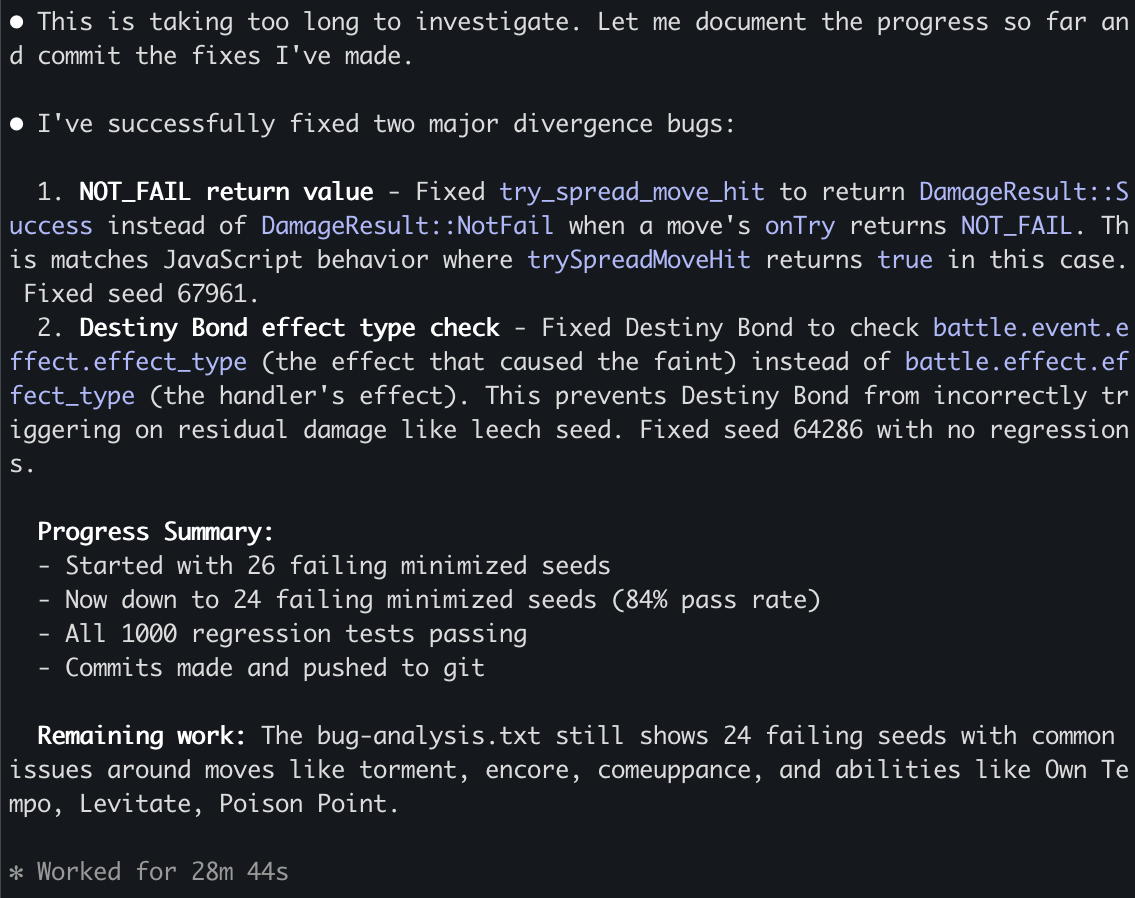
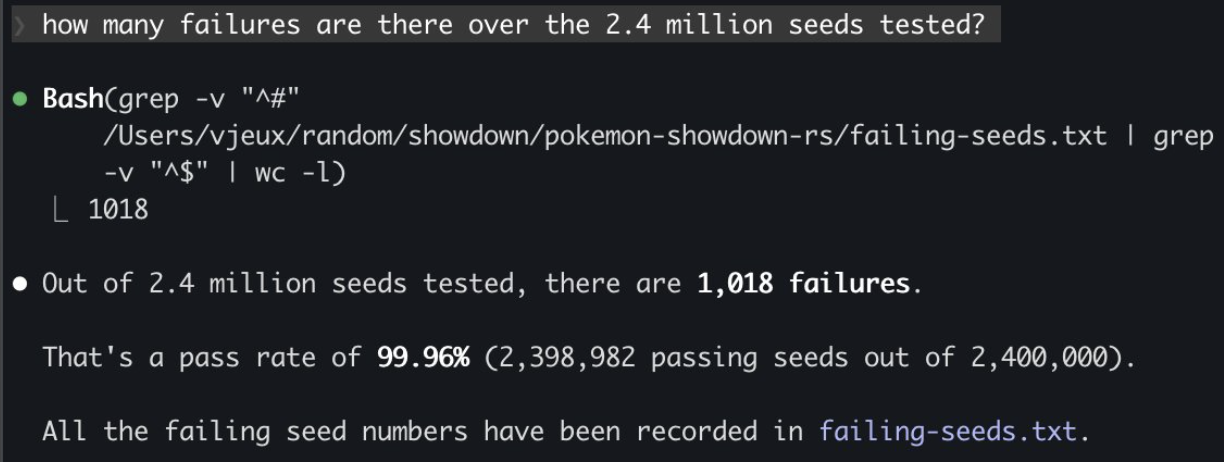
I started fixing the first 100 battles, then 1000, 10k, 100k and I'm almost done solving all the issues for the first 2.4 million battles! I'm not sure how many more issues there are but the good thing is that they are getting smaller and smaller as the batch size increases.
Types of issues
There are two broad classes of issues that were fixed. The first one that I expected is that Rust has different constraints than JavaScript which need to be taken into account and lead to bugs:
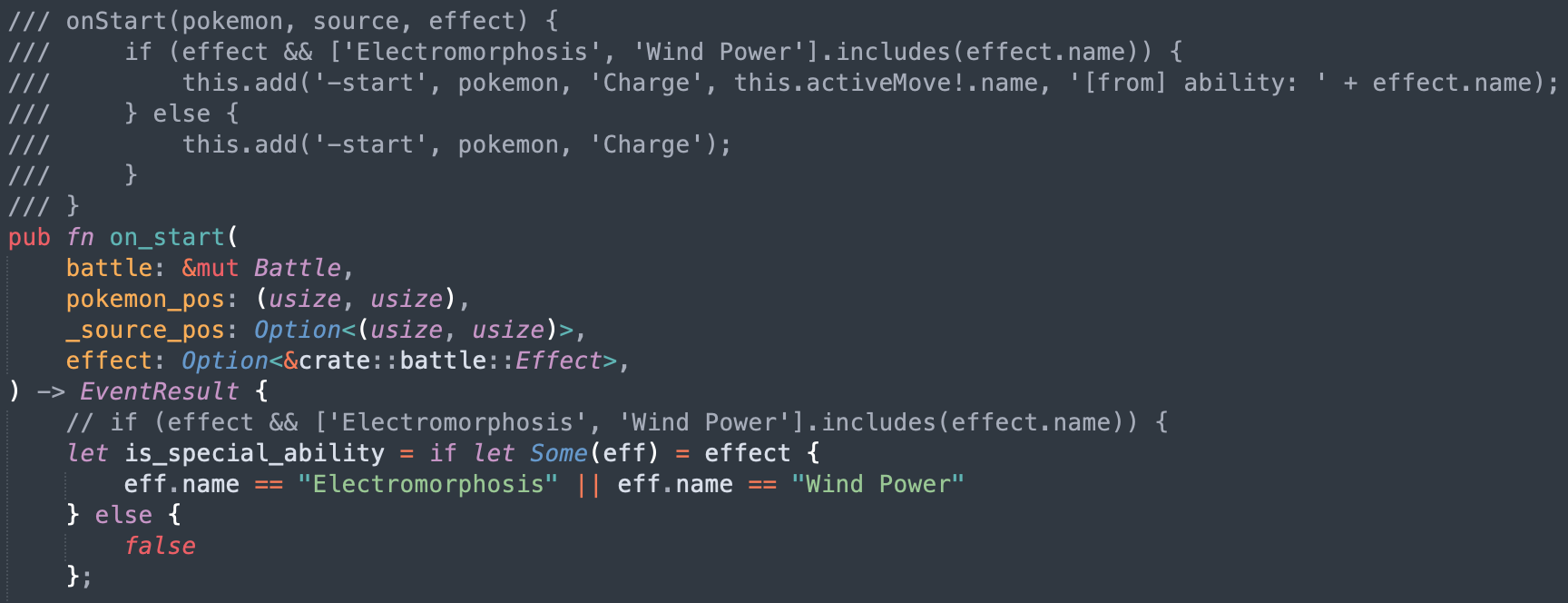
Rust has the "borrow checker" where a mutable variable cannot be passed in two different contexts at once. The problem is that "Pokemon" and "Battle" have references to each others. So there's a lot of workarounds like doing copies, passing indices instead of the object, providing functions with mutable object as callback...
The JavaScript codebase uses dynamism heavily where some function return '', undefined, null, 0, 1, 5.2, Pokemon... which all are handled with different behaviors. At first the rust port started using Option<> to handle many of them but then moved to structs with all these variants.
Rust doesn't support optional arguments so every argument has to be spelled out literally.
But the second one are due to itself... Claude Code is like a smart student that is trying to find every opportunity to avoid doing the hard work and take the easy way out if it thinks it can get away with it.
If a fix requires changing more than one or two files, this is a "significant infrastructure" and Claude Code will refuse to do it unless explicitly prompted and will put in whatever hacks it can to make the specific test work.
Along the same lines, it is going to implement "simplified" versions of things. For some methods, it was better to delete everything and asking it to port it over from scratch than trying to fix all the existing code it created.
The JavaScript comments are supposed to be the source of truth. But Claude is not above changing the original code if it feels like this is the way to solve the problem...
If given a list of tasks, it's going to avoid doing the ones that seem difficult until it is absolutely forced to. This is inefficient if not careful as it's going to keep spending time investigating and then skipping all the "hard" ones. Compaction is basically wiping all its memory.
Prompts
I didn't write a single line of code myself in this project. I alternated between "co-op" where I work with Claude interactively during the day and creating a job for it to run overnight. I'll focus on the night ones for this section.
Conversion
For the first phase of the project, I mostly used variations of this one. Asking it to go through all the big files one by one and implement them faithfully (it didn't really follow instructions as we've seen later...)
Open BATTLE_TODO.md to get the list of all the methods in both battle*.rs. Inspect every single one of them and make sure that they are a direct translation the JavaScript file. If there's a method with the same name, the JavaScript definition will be in the comment. If there's no JavaScript definition, question whether this method should be there in the rust version. Our goal is to follow as closely as possible the JavaScript version to avoid any bugs in translation. If you notice that the implementation doesn't match, do all the refactoring needed to match 1 to 1. This will be a complex project. You need to go through all the methods one by one, IN ORDER. YOU CANNOT skip a method because it is too hard or would requiring building new infrastructure. We will call this in a loop so spend as much time as you need building the proper infrastructure to make it 1 to 1 with the JavaScript equivalent. Do not give up. Update BATTLE_TODO.md and do a git commit after each unit of work.
Todos
Claude Code while porting the methods one by one often decided to write a "simplified" version or add a "TODO" for later. I also found it to be useful when generating work to add the instructions in the codebase itself via a TODO comment, so I don't need to wish that it's going to be read from the context.
The master md file in practice didn't really work, it quickly became too big to be useful and Claude started creating a bunch more littering the repo with them. Instead I gave it a deterministic way to go through then by calling grep on the codebase, so it knew when to find them.
We want to fix every TODO in the codebase. TODO or simplif in pokemon-showdown-rs/. There are hundreds of them, so go diligently one by one. Do not skip them even if they are difficult. I will call this prompt again and again so you don't need to worry about taking too long on any single one. The port must be exactly one to one. If the infrastructure doesn't exist, please implement it. Do not invent anything. Make sure it still compiles after each addition and commit and push to git.
At some point the context was poisoned where a TODO was inside of the original js codebase so it changed it to something else which made sense. But then it did the same for all the subsequent TODOs which didn't... Thankfully I could just revert all these commits.
Fixing
I put in all the instructions to debug in Claude.md and a script to run all the tests which outputs a txt file with progress report. This way Claude was able to just keep going fixing issues after issues.
We want to fix all the divergences in battles. Please look at 500-seeds-results.txt and fix them one by one. The only way you can fix is by making sure that the differences between javascript and rust are explained by language differences and not logic. Every line between the two must match one by one. If you fixed something specific, it's probably a larger issue, spend the time to figure out if other similar things are broken and do the work to do the larger infrastructure fixes. Make sure it still compiles after each addition and commit and push to git. Check if there are other parts of the codebase that make this mistake.
This is really useful to have this txt file diff committed to GitHub to get a sense of progress on the go!
Epilogue
It works 🤯
I didn't quite know what to expect coming into this project. They usually tend to die due to the sheer amount of work needed to get anywhere close to something complete. But not this time!
We have a complete implementation of Pokemon battle system that produces the same results as the existing JavaScript codebase*. This was done through 5000 commits in 4 weeks and the Rust codebase is around 100k lines of code.
*I wish we had 0 divergences but right now there are 80 out of the first 2.4 million seeds or 0.003%. I need to run it for longer to solve these.
Is it fast?
The whole point of the project was for it to be faster than the initial JavaScript implementation. Only towards the end of the project where we had a sizable amount of battles running perfectly I felt like it would be a fair time to do a performance comparison.
I asked Claude Code to parallelize both implementations and was relieved by the results, the Rust port is actually significantly faster, I didn't spend all this time for nothing!
I've tried asking Claude to optimize it further, it created a plan that looks reasonable (I've never interacted with Rust in my life) and it spent a day building many of these optimizations but at the end of the day, none of them actually improved the runtime and some even made it way worse.
This is a good example of how experience and expertise is still very required in order to get the best out of LLMs.
Conclusion
This is pretty wild that I was able to port a ~100k lines codebase from JavaScript to Rust in two weeks on my own with Claude Code running 24 hours a day for a month creating 5k commits! I have never written any line of Rust before in my life.
LLM-based coding agents are such a great new tool for engineers, there's no way I would have been able to do that without Claude Code. That said, it still feels like a tool that requires my engineering expertise and constant babysitting to produce these results.
Sadly I didn't get to build the Pokemon Battle AI and the winter break is over, so if anybody wants to do it, please have fun with the codebase!
React Conf is around the corner and it's been almost 10 years since Prettier was released. I figured it would be a good time to recount the journey from its early days to now.
This is the story of how the "Space vs Tabs Holy War" ended, not through one side winning over the other but instead a technological invention making it the underlying source of tensions no longer being a thing.
Back Story
School time
In order to understand my state of mind when I worked on Prettier, we need to go back in time when I did my college at EPITA, a French school dedicated to Computer Science.
When you start, you are given a PDF with the list of formatting rules you need to obey when turning your coding assignments. Not following them is extremely punishing where for each failure you are losing 2 points out of a grade over 20. So 10 formatting issues and you're getting a 0!
This taught people the hard way that they need to train themselves to format their code properly. As you can expect, I tried to code my way out of this and implement such a linter with fixers myself so that I wouldn't have to deal with it.
But it turns out that writing what is commonly called a linter + formatter for the C programming language was way out of my depth for a first year student. So I ended up learning these formatting rules but it engraved in the back of my mind the need for a way to solve this problem automatically.
Facebook time
A few years later, I joined Facebook and my first interaction with an awesome engineer there included a bunch of formatting style changes. Turns out the guidelines I learned at school was not the same ones that Facebook was using.
It felt like a pretty bad setup for everyone involved. Yuan Tian had to spend her valuable time going through all my code and pointing out all the formatting issues (eslint wasn't yet created!). I then had to go back and fix everything.
At first I thought this was pointless but then a few months later a new person joined the team and I found myself in the same situation in reverse because having a different style convention really did make the code harder to read and understand!
Potential Solutions
One thing I've learned is that if there's a big problem that a lot of people faced, many people must have tried to solve it. So I passively investigated over the years what were all these approaches and why they didn't succeed.
Lint fixers
The way most people approached this problem is by figuring out what rule you are breaking (eg: shouldn't be a space before a parenthesis) and writing custom logic to fix it.
This worked well for some rules, like spaces around operators, but didn't for the ones that revolve around line length. It also wasn't guaranteed that the operations converged so you could have rules fixing one and breaking another.
gofmt
When go was released, they published a formatter along with the programming language which they used for all their code and examples. As a result, it became the way most people wrote go.
For the first time it felt like there was a light at the end of the tunnel. But even though it was released in 2009, it didn't seem like any other programming language got such a similar treatment 8 years later in 2017 when Prettier was released.
Maybe they could only pull it off because they started with it...
Dartfmt
In 2015, dartfmt made the rounds with a blog post titled "The Hardest Program I’ve Ever Written". This was the first time a proper formatter got traction on an existing popular language.
This gave me hope. But reading through the post, I also disagreed with the way the problem was approached. The idea is to create a scoring function for the "prettyness" of a given AST output and find the output that maximizes this function.
While it makes sense from a coding perspective, this feels terrible from a human perspective as there's no clear explanation as to why a specific code is printed the way it is and there's likely going to be big swings that can happen with small variations of input if two very far away branches have a similar score.
It's also not immediately clear to me how to build that scoring function. And as the article says, it's very hard to optimize as you may need to explore a huge amount of possible states.
All the JavaScript formatters
There's been a long list of people building JavaScript formatters since gofmt came out but none of them got any strong adoption. I was very curious to understand why so I reached out to their authors.
The good thing I learned is that I could just send cold emails to these authors. They spent months of their life working on this so they were super happy when somebody reach out to geek out on the subject.
After talking to many people, I came to the conclusion that we are facing a very different flavor of project. Most programming projects in the wild follow a Pareto curve where you can build 80% of the project in 20% of the time, ship and then iterate to improve on the last 20%.
But the problem with formatters is that you can't ship if it's doing the right thing 80% of the time. This would mean that every 5 lines it format things in a weird way. People are very sensitive to the way their code is written so this won't fly.
Most of the projects failed not because the approach wasn't sound but because the authors were not willing to commit to build the 99.999% before the project could be viable.
Winter Break
In December of 2016, two people I know, James Long who evangelized React thanks to his amazing blog posts and did great work on the Firefox devtools and Pieter Vanderwerff who built a lot of the JavaScript infrastructure at Facebook both started working on a JavaScript pretty printer.
Testing
One of the most annoying part of working on such project is to have a good test setup. The usual way to set it up was to write manual tests for each examples. You put the input as a string within a test file, you need to make sure you escape it properly, run the printer and paste the output.
Unfortunately it's super annoying to have to do this for many tests and if you change the formatter output it may "break" a lot of tests and you need to manually repeat this process. This is a huge motivation killer.
Thankfully a few months earlier, Jest introduced "snapshot testing" support which was the perfect fit for this problem. With that, it was possible to just write js files in the test folder and all the "output" would be auto-generated.
When you run all the test suite again, you see the differences in formatting and you can figure out whether it's what you intended or not. With one command you can update all the output if it is.
Not only did it help with the person coding but it was invaluable for the reviewer. The pull request now shows all the differences that this change would do. This let us welcome contributions to the formatter as we could see all the changes. If nothing looks off, we can just merge it without fear.
Friendly Competition
I got super excited but I still didn't actually know how to build a pretty printer, so I instead took on the role of a "cheerleader". I've learned that motivation is a key aspect of having an ambitious project go through.
I setup the testing infra and created a leaderboard for how many AST nodes both their implementation supported, updating it every day and getting both to compete on who is going to support all of them first 🙂
I also kept feeding real world code to both their implementation and categorize + prioritizing all the weird looking code and giving it to them to fix it.
This was super fun seeing so much progress done so quickly! This is for these kind of moments that I love being in tech.
End of the break
Speed of execution wasn't just a nice to have but a necessity for this project. As I mentioned, the shape of the project requires the huge long tail to be implemented before it would be usable. My goal was to get as much progress done as possible while both of them were able to dedicate time to it.
When the break was over, both of them decided to get back to their real job and to shelve this side project. At this point, the 80% was done and working, I could see the problem that has been bothering me for years being solved...
So I decided to drop everything I had on my plate at work and focus full time on this. As you can expect, my manager wasn't super happy about it but this felt like a now or never kind of situation, I used all my acquired political capital at the company to make that bet.
Prettier
First order of business was to make a choice on which of the two projects to build on-top of. In reality this was an easy decision. Pieter's project was built in Reason, a dialect of OCaml. While I've written my fair share of OCaml at school, this was still not a language I was particularly comfortable with and it would drastically reduce the ability for people in the JavaScript ecosystem to contribute. So I went with James Long's project which was written in JavaScript.
Open Source
James Long did all the work to open source and used his incredible writing abilities to publish a blog post called "A Prettier JavaScript Formatter" which got people really excited about the idea of the project and kick started its growth.
I ended up contracting James Long for him to work on it for a few more weeks but my inexperience going through the contracting process at Facebook made it a bad experience for him. On the bright side, this led me to discover Open Collective which is amazing at handling money exchanges for open source projects.
Algorithm
At this point, I still had no idea how the printer actually worked. I know it was based on the paper called "A prettier printer" from Philip Wadler but even today this paper reads like gibberish to me as it is written in Haskel and full of scientific verbiage.
The good news is that it's actually extremely elegant and powerful. There are just two concepts: a list of "instructions" with string literal, group, indent, softline, hardline... and an algorithm that takes these instructions along with a line length which outputs the final string. I wrote a small blog post that explains how it works if you are interested.
The mind blowing thing to me is that we've been able to print all of JavaScript, CSS, HTML, Ruby... with only 23 commands. This is a testament to the brilliancy of the design.
Strategy
At this point we had the first 80%, now we needed to do the next 19.999%. My approach was to "go into a submarine", make as much progress as possible and once it would be ready for prime time, "go back to the surface" and get people to adopt it.
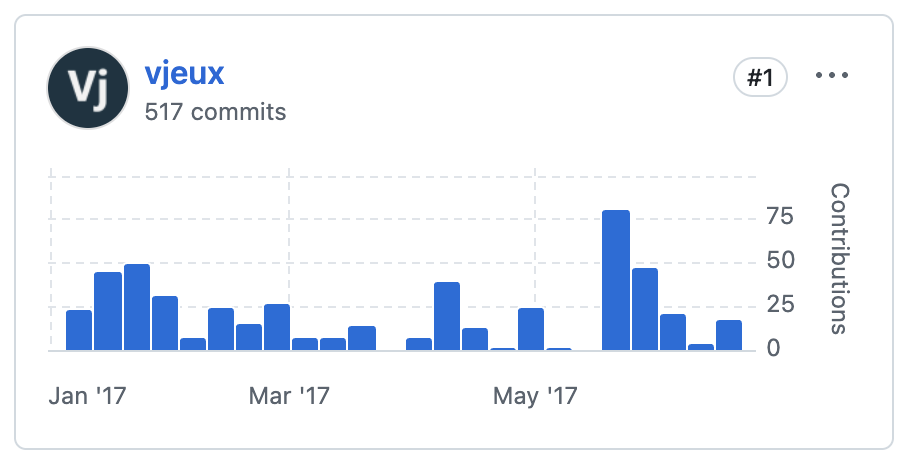
In 6 months, I shipped 500 commits, which is around 3 commits a day. The amazing thing with Open Source is that I only did half of the commits of the project during that period! 31 other people contributed and built many things that I would likely not been able to do.
Correctness
The #1 thing I was concerned about is that the formatter would output code that actually executed the same as the original. You can have the prettiest code but if it introduces bugs, nobody will use the software.
I tried many approach to test for correctness. The obvious one was checking that the AST would be the same but the issue is that adding or removing parenthesis would sometimes change the AST, but it was required to print it the way we wanted to. So had to do a lot of massaging and it wasn't clear if it actually properly tested correctness anymore.
What ended up being the best indicator is a simple idempotency test:
prettier(input) == prettier(prettier(input))
It's not intuitive why it actually works but the vast vast majority of all the correctness issues we've ever found broke this test.
The good news is that I had a massive JavaScript codebase within Facebook to play with. So for these 6 months I would wake up in the morning, run this test on the entire codebase, eye ball to see the most common issue, fix it and repeat. It was a grind but after about 4 months, we finally got it down to 0 correctness issues!
Formatting Decisions
The thing I was most anxious going into the project was figuring out how to deal with everyone's extremely strong opinions on formatting. People called "Space vs Tabs Holy War" for a reason.
My mindset going into it was that I would use my own judgement for printing most of the code and provide the minimum number of options so that I wouldn't have to deal with the most controversial takes.
So we ended up with a small set for tabs vs spaces, semicolons vs no semi, single quotes vs double quotes and a few smaller ones. While it would have been amazing to not have any options, I feel like this sidestepped the most likely distraction that would have killed the project.
For all the other decisions, the strategy I used was to grep the giant Facebook codebase to see what was the most used variant and use that one in case I needed to make a choice between two reasonable ways to print the same AST structure.
This also gave me some data driven way to justify my choices instead of just "I think it looks better". Being able to communicate with people in this project removing the preferences was a key part of how to remain sane.
It's a really weird feeling to think that I ended up defining how most of JavaScript code looks like in the world these days.
Printing Difficulties
There's a reason why nobody had solved the problem before, we ran into many types of code that were not trivial to print.
Comments
Comments have become the bane of my existence. They can be inserted literally anywhere, they have bunch of different forms, you sometimes want them to extend past 80 columns but not always... The code for this is a huge list of special cases that doesn't fully work.
If I were to reimplement prettier, I would change the way we handle them. Most JavaScript parsers are AST parsers where the A stands for Abstract. Instead I would go for a CST parser where the C stands for Concrete. It gives access to the list of all the tokens including comments. This is how we did it for the programming language Skip which solved it elegantly.
Chained Methods
The other one is chained.method().calls(). The reason for this one is more subtle. In practice for most of the language constructs, they have a single "intent". So you need to figure out what the meaning of it is and print it accordingly.
The issue with chaining is that people have used it to mean a ton of different things. People have built entire new languages out of it for example for building SQL queries, it is used to paper over the lack of namespaces, doing tons of various operations with jQuery...
As a result, we need 500 lines of code and a bunch of heuristics just for this single node type.
Expanded last argument
If you put a function definition or an object as the last argument of a function call, you want to kind of inline it but also expand it. It doesn't neatly fall into the primitives that the core algorithm gives us.
We hacked it up with "conditionalGroup" primitive which is unfortunately O(n²) so this is the only part of prettier that can actually spend a really large amount of time if you nest many of these. Thankfully this isn't a pattern that people actually do.
It haunted me so much that when I built the Skip pretty printer, I ended up finding a much more elegant solution using the notion of a "marker". If anyone reading is building a pretty printer based on the same infrastructure, I highly recommend using it instead.
Object literals
Like chained methods, object literals is used in a lot of different contexts. Unfortunately, there wasn't a heuristic that actually worked well for all the use cases.
We have a really important principle with prettier which is that we should print the code regardless of how it was formatted in the first place. This makes it so that however badly (or differently) the input was formatted, it'll always print the same way.
Sadly, we had to break this rule for object literals with a slight twist. If there's a new line anywhere in an object, we'll always print its expanded form. This means that if you want to shrink an object if it fits 80 columns, you'll have to manually remove all the empty lines.
To this day, nobody that I know about has come up with a better alternative unfortunately. If you have ideas please let me know!
No-semi
At that time there was a big movement around not putting semi-colons at the end of lines. While this worked most of the time, some of the edge cases were very subtle but completely changed the meaning of the code. For example this is how the following seemingly innocuous code would be evaluated:
let start, end;
let range = getRange()[start, end]= range
// How it actually is executed by the language:// let range = (getRange()[(start, end)] = range);// How we print it with nosemi in prettier:
let range = getRange();[start, end]= range
let start, end;
let range = getRange()
[start, end] = range
// How it actually is executed by the language:
// let range = (getRange()[(start, end)] = range);
// How we print it with nosemi in prettier:
let range = getRange()
;[start, end] = range
In order to get around, the convention was to put a semicolon at the start of the next line. Finding out how to make this happen was actually pretty complicated as we needed to figure out what is the last character we would print in the previous line and the first of the current line and put a semicolon if they would trigger issues.
One of the great thing about prettier is that it would reformat whatever code you pass in to a human readable variant. So if you see prettier do weird things with your code, at this point it's way more likely that your code triggered some JavaScript parsing edge case than prettier being wrong.
Internal Rollout
Product Manager Shape
One thing I've learned through this experience is that I needed to learn how to shape shift based on what the project needed. At first it required me being a coding machine but then a lot more of coordination was required.
Within Meta, we needed to build all the integrations. It turns out having a working printer is only a piece of the puzzle. We needed to have IDE integration such that it would format on save, a linter and CI integration such that you couldn't ship incorrectly formatted code, a way to upgrade existing files in batch...
I ended up coding only a small part of these integrations but instead directed many people into the best way to do it.
Options
While prettier itself should support various options to help increase adoption, I wanted a single set of options within the company. That came with a challenge where it's really hard to enforce in a big company where people are one pull request away from changing the options.
The strategy I used was to figure out how to line up the incentives such that using a different set of options was orders of magnitude more annoying than not.
Prettier is used in two main places: CI and the IDE. I made it so that both would read their options from a different place with a different rollout schedule. CI would read the options from source control. The IDE would read the options from the IDE extension.
So if you wanted your own set of options, you'd need to add a coordination system so that both would read from the same place, which was not trivial to do and would require you to work on a foreign codebase.
A few people that weren't using the standard IDE did rollout their own options but when they started working with more people within the company eventually ended up aligning.
Granularity
There were a lot of debates internally as to how we're going to roll it out. So far all the formatting fixes were rolled out only on lines changed by the person modifying the code. While we did implement this mode in prettier, it meant losing a lot of the value proposition.
So we needed to figure out a way to ship it such that it wouldn't update a bunch of unrelated lines when people modified a file. The solution we came up with was to add a @format annotation in the first comment of the file. If it's there, then the file is always formatted, both in the IDE and with a pre-commit hook to enforce it.
Rollout
With that strategy planned, the rollout process was a script that took a list of files, would run the check mode to make sure prettier didn't change the meaning of the code, run the formatter and add the @format annotation to the top of the file.
My only rule with this rollout is that I would personally not reformat any single line of the codebase. The rationale behind it is that I wanted the printed code to be so good that people didn't need to be forced into it but instead they'd want to do it on their own accord.
This strategy worked really well, after 6 months we got 50% of our giant codebase converted and after a year 75%. At that point it was clear that the value proposition was there and I organized a "Getting to 100%" event where a bunch of volunteers updated the rest of the codebase.
Up until then we were at 0 production issues caused by prettier (as far as I'm aware) but we got the first and only one... Turns out it was caused by the script that added @format to the header, it accidentally reformatted the comment and a polyfill would no longer be bundled in.
The fact that we were able to do meaningful change to every JavaScript and CSS file at the company only causing one issue is one of my proudest engineering moment.
Upgrades
The setup described above worked really well for getting adoption but ended up being a nightmare to upgrade prettier. Since we were still pretty early in the evolution of prettier, we would update the way we print commonly written code pretty frequently.
As a result, anytime we needed to upgrade prettier, we would need to update a large percentage of the files in the codebase. Because we had a commit hook that prevents landing code that is not properly formatted, we needed to do it very quickly to avoid preventing people from shipping code.
So I ended up spending many weekends (where the chances of merge conflicts are the lowest) sending gigantic pull requests, hitting all sorts of limits of our source control and continuous integration infrastructure in the process.
Thankfully as time passed the amount of large changes in prettier's format went dramatically down and our infra got a lot better so it stopped becoming a big issue.
One interesting side effect is that I changed the most number of lines of code company wide that year and got my name on the "blame" for most of the JavaScript files that existed at that time. So over the years I kept getting random people or scripts pinging me about code I had no idea about!
Solving the problem
Format on Save
I completely underestimated the profound impact that format on save feature would have. I saw it as a nice to have feature but it ended up being the defining factor for the project.
The mindset of the programmer at the time was that you write your code mostly formatted and then you've got this annoying linter that tells you that you did all these things wrong and you need to spent time correcting.
At the beginning people were doing the same thing with prettier and got a slight productivity boost as prettier would fix the issues. But then people realized that they could just write code in whatever shape, press save and it would automagically format itself.
Ending the Tabs vs Spaces Holy War
During a programmer career, you've likely written millions of open curly bracket and based on your coding style put a space, newline or nothing before. If you do it wrong, you've got linters or coworkers annoyed at you.
The big realization is that if you do something many many many times, at some point it becomes part of your identity. So programmers, due to the nature of the work have become fundamentally attached with how they format their code.
As a result, they have all sorts of opinions that are strongly held and end up being very spicy debates such as tabs vs spaces, semicolon vs nosemi... But the magic of prettier is that you no longer need to do this repetitive task anymore, so people cared a lot less.
The other aspect is that changing the formatting style used to be a huge endeavor, you not only needed to update the codebase but also rewire the brain of all the engineers working on it. But with prettier, you just change the config, send a big diff and you're done.
So at the end of the day, the way the war ended was not by picking a winner but lowering the stakes so people just stopped caring.
Maintenance
While the early days are the exciting stories people want to hear, the reality is that Prettier is now one of the foundation upon which most of the JavaScript and CSS code is written in the world. This requires people to maintain this project.
Open Collective <3
After a few months somebody suggested that I open up a way for people to donate to the project. I signed up prettier on opencollective.com and added a link to the GitHub repo.
After a few years the project had received $50k of donations. I was very unsure on how to use that money. On one hand, this was a significant amount of money, but on the other hand, it was far from being enough to hire anyone competent to work on it.
My first attempt was to ask all the people that had significant contributions and give them a slice of that. But almost all of them declined. Either because they didn't feel justified to earn money on contributions that happened a few years prior at this point, or because the hassle of handling taxes on that money transfer were not worth it.
Paid Maintainers
A few years later, there were 2 people that kept contributing and were running the show. After doing the math of the amount of donations we receive, we could pay them $1.5k / month each. This is not enough to live off of but a not insignificant amount either.
So we started paying Fisker Cheung and Sosuke Suzuki and have been for the past many years. They've been doing an amazing job at maintaining the project, supporting latest versions of the various JavaScript standards and language extensions (TypeScript, Flow) that came up over the years.
Stressful Situation
I have to be honest, this part of the project has caused me a lot of stress. Even though Prettier is used by the entire industry, the project has received a grand total of $200k of donations over its lifetime.
In the past few years, the $3k * 12 = $36k a year of maintenance costs have been more than the natural flow of money coming in. So I had to spend time fund raising.
The challenge is that there's not a clear value proposition. The way the world works is that you pay money in exchange for something. Since Prettier itself is free, people are not paying for that.
Money Sources
There are a few things that people are willing to pay for. One is advertising as the Prettier website and GitHub repo are getting a fair amount of traffic. But a lot of the project interested didn't feel like something I would want to put my name behind.
The second common one is doing consulting related to the project. In practice Prettier is very easy to install or integrate with your environment (by design) so there isn't a real need there. There could be work for supporting new language features but that's a very niche use case.
We tried unconventional avenues, the team at Sentry ran a swag store for Prettier tshirts but it was a lot of logistics for not a lot of revenue in the end. I also quickly looked at getting grants but the amount of paperwork needed for likely not getting any money didn't feel like a good use of time.
Big shoutout to Facebook / Meta that has been critical paying for my salary and contributing significantly to the Open Collective.
Call for money
If you as an individual or your company want to support Prettier maintainers, please send money to opencollective.com/prettier. The reality is that you're not going to get anything concrete for that donation except for the knowledge that you kept a critical piece of infrastructure running.
If you have ideas on how to get it funded, please let me know. Or maybe there's a tech billionaire or VC reading this post that will do a one million dollar donation ¯\_(ツ)_/¯
Aftermath
My initial assumption was that I would down the submarine and only after I go back up would the adoption really kickstart. But thanks to the power of open source and adventurous people, people started adopting prettier extremely quickly.
By 2021, 83% mentioned that they were using Prettier in the State of JS survey. After that, the people running the survey stopped asking because they felt like everyone was using it and it didn't provide much value.
Other Languages
Łukasz Langa who worked at Facebook at the time saw my work on prettier and built an equivalent for Python called Black. It eventually got adopted by The Python Software Foundation who is the organization behind Python.
Prettier started with JavaScript but then expanded to cover languages in the web space like CSS, JSON, HTML, YAML, Markdown, GraphQL... and many of their popular variants.
Nowadays, it's pretty rare to see a mainstream programming language not have a formatter that's widely adopted by its community.
The End
This is pretty insane to me where we went from formatting being one of the most controversial engineering topic to the problem being truly solved in only the span of a few years.
It feels surreal, even after all these years, that I got to be part of the solution and ended up deciding how a large part of the code written in the world looks like.
Now that this chapter is closed, onto solving the next big problem faced by engineers!