A school project was to find the shortest path in a dungeon graph. You start with an amount of hit points, and each edge gives or removes hit points. You have to find the path from two points going through the minimum of edges (no matter their value) alive (hp > 0 all along the path). The difficulty here is that you have to go a finite amount of time through absorbing cycle to complete interesting graphs. Here is the full subject.

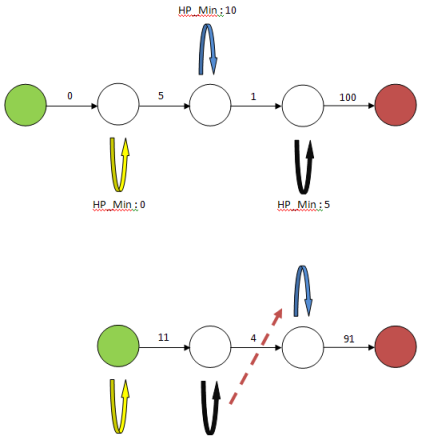
Example: dungeon graph
Example: You start with 10 hp. The shortest path is [1, 2], [3, 4, 2] * 492, [3, 5]. You notice that you have to loop a huge number of time on the [3, 4, 2] cycle that gives you 1 hp per run.
The common solutions were either a custom Breadth First Search or Dijkstra algorithm along with a heuristic. It is easy to write, always gives the shortest path and have space for improvement. However, it has a major flaw: it doesn't scale well with high values. Instead of 500, put 50 000 000 and it will run forever.
My approach is to detect the cycles and find the best cycle organization. In this example, you would notice that [3, 4, 2] is a cycle that takes 3 edges and gives 1 hp. You come to this cycle with 9 hp, you need to pass with 501 hp so you need to take this cycle (501 - 9) = 492 times.
Finding Atomic Paths & Cycles
Definition
What we want to do is find all the possible paths going from point A to point B. Since there are cycles involved, you can't just go through and enumerate them all. Instead, you will have to find atomic path that doesn't loop and the smallest possible cycles (you don't want your cycle to repeat itself).
The first definition I took of an atomic path is a path that does not go through the same node twice. However, I found out that is was not taking all possibilities. After some reflexion, I figured out that nodes aren't important, however edges are! So an atomic path is a path that does not go through the same edge twice.
This definition is handy, it also works for cycles: an atomic cycle of point A is an atomic path that goes from point A and ends to point A.
Implementation
Atomic Paths A -> B
In order to get all the path starting from point A, we are going to traverse the graph recursively from the point A. While going through a child, we are going to make a link child -> parent in order to know all the edges we have already crossed. Before we go to that child, we must traverse that linked list and make sure the specified edge has not been already walked through.
When we arrive to the destination point, we can store the path we found.
Freeing the list
A problem occurs when you want to free the linked list. It is basically a tree chained in the reverse order. A solution would be to double-link that list and when all the atomic paths been found, free the tree from the starting point.
But a clever solution is to use a reference counting (inspired from Garbage Collection). Each time you add a link to a parent you adds one to its reference count. Then, when you arrive at the end of a path, you go backward and free while the reference count equals to 1. If it is higher, you just remove one and stop.
Atomic Cycle A
Looking for the atomic cycle of A is the same as looking for the atomic path from A to A. However there are several optimizations we can do. First, when we arrive at the destination point, we want to save the path only if the sum of the edges cost is negative: we only want to go through absorbing cycles.
As you have seen previously, the whole graph is being traversed when looking for an atomic path. Instead, we can limit the search area to the strongly connected component containing A. Finding these components requires a simple traverse of the graph with Tarjan's algorithm.
Combining Atomic Paths and Cycles
At this point, we have all the atomic paths that goes from A to B and all the atomic cycles of each node, left to us to organize everything to get the shortest path. From now on we are going to study how to find the best combination of atomic cycles in an atomic path.
In order to see the problem, we can use a digression. Imagine a plane that wants to cross a mountain. The only way to get up is to stay on hot air spot for a while. He has to chose the best combination of spots in order to go over each peak loosing as little time as possible.
Atomic Cycle Characteristics
Absorbing cycles can only be unlocked when moving through the path. In the example, the cycle [3, 4, 2] is only available after being on the node 2. So you have to have 1 hp to get to node 2 and 1 more hp to get to node 3 and then be able to get the -3 bonus. This highlights an important characteristic: minimum hp. Each cycle and node have a minimum hp to be visited.
We are now able to fully describe an atomic cycle with these four characteristics:
- Entry point
- Edge count
- Cost (negative)
- Mininum hp
Nodes to States
Atomic cycles have an inner minimum hp, hence, this is not possible to merge them with their entry point. We have to make a virtual state representing the possibility to walk that cycle. The condition of that state is having at least node minimum hp + cycle minimum hp. This way we can define a state minimum hp.

Example: Node to State
In the example, the third node has a minimum hp of 1 + 2 and the yellow cycle has a minimum hp of 1, so the resulting state has a minimum hp of 4.
Warning: This technique is subject to overlapping. I did not find an efficient way to handle this case so it can generate wrong result.
Greedy Combination
What we have now is a list of states, each one unlocking one or more cycles. We have to find the best combination of cycles.
We have first to define what is the best cycle. There can be two definitions based on the ratio hp / edge.
- Global ratio: The one that gives the most hp per edge.
- Local ratio: The one that goes from A to B with the less number of edges
We could be tempted to use the global ratio but this is not a good idea. Imagine you need to get 2 hp to go to the end. You don't want to use the cycle that gives you 1 billion hp for only 100 edges when there is a cycle that gives you 2 hp for 10 edges.
A simple algorithm to find a good solution is to take the cycle with the best local ratio available at state A enough times to go to state B, then repeat the same process with cycles available at state B to go to state C and so on.
This works great but is too much subject to local errors. Let say you have the two cycles of the previous example available at state A and you want to go to state Z that is 200 hp away with small steps between. You will always choose the cycle that gives you 2 hp for 10 edges and end up with 200 edges when you could have used the 1 billion hp for 100 edges in the first time.
A solution is to sophisticate the algorithm a little. Instead of doing [A -> B -> C -> D], we are going to do
[A -> B -> C -> D], [A -> C -> D], [A -> B -> D] and [A -> D] and see what's best. This is more processing but gives much better results.
Warning: This method does not give the best possible combination, only an approximation. Also, it does not handle cases were a combination of multiple cycles is better than a single cycle to go from one state to another.
Optimizations
Before attempting to compute an atomic path, take the cycle with the best global ratio available and see how many edges would be necessary to get to the end with that ratio. If that's superior to the already found shortest path, it is worthless to do it. This simple test should allow you to skip the majority of the paths.
When you are generating the states, you do not have to take care of cycles when there is a better one available before. A better cycle is a cycle that has less edges for the same amount of hp. This reduces the number of states, therefore by a great factor the number of combinations needed in the sophisticated algorithm.
Conclusion
Advantages
Complexity edge value independent
The main advantage of this method is that the complexity depends of the number of nodes and the density of the graph but is not affected by edge values. If you set the critical edge to be 50 or 50 000 000, this will give you the result in the same time. However, the time required increases faster with the number of nodes than the basic method.
Parallelizable code
To compensate, the code becomes parallelizable. During the first step, you can give each atomic path and cycle detection to different computers at the same time. Then, each path can be computed no matter the order.
Low memory output
The main problem with the basic method is memory allocation. For each node of the final and potential (to some extent) paths a memory chunk is allocated. When you are testing you usually do it with long paths and memory becomes really fast the limiting factor.
Disadvantages
Much more code
The resulting code is much bigger than the basic method. This means a longer development time, more bugs.
Not perfect result
The real problem are the edge cases when it does not return the shortest path or worse, when it gives an invalid path. The three problems are the overlapping issue when converting nodes to states, the greedy algorithm to find combinations and finally the single-only cycle to go from one state to another.
I don't know if all of them could be fixed without seriously affecting the complexity of the algorithm.
Is strongly depending of the size of the graph
Since the algorithm does a brute force of all possibilities, the complexity goes exponentially with the size of the graph. However, in the case of the project, we were told that only small (no more than 50 nodes) would be tested.

{kind=link}